Metabolic Syndrome Prediction Using Machine Learning Models with Genetic and Clinical Information from a Nonobese Healthy Population
Article information

Abstract
The prevalence of metabolic syndrome (MS) in the nonobese population is not low. However, the identification and risk mitigation of MS are not easy in this population. We aimed to develop an MS prediction model using genetic and clinical factors of nonobese Koreans through machine learning methods. A prediction model for MS was designed for a nonobese population using clinical and genetic polymorphism information with five machine learning algorithms, including naïve Bayes classification (NB). The analysis was performed in two stages (training and test sets). Model A was designed with only clinical information (age, sex, body mass index, smoking status, alcohol consumption status, and exercise status), and for model B, genetic information (for 10 polymorphisms) was added to model A. Of the 7,502 nonobese participants, 647 (8.6%) had MS. In the test set analysis, for the maximum sensitivity criterion, NB showed the highest sensitivity: 0.38 for model A and 0.42 for model B. The specificity of NB was 0.79 for model A and 0.80 for model B. In a comparison of the performances of models A and B by NB, model B (area under the receiver operating characteristic curve [AUC] = 0.69, clinical and genetic information input) showed better performance than model A (AUC = 0.65, clinical information only input). We designed a prediction model for MS in a nonobese population using clinical and genetic information. With this model, we might convince nonobese MS individuals to undergo health checks and adopt behaviors associated with a preventive lifestyle.
Introduction
Metabolic syndrome refers to a state in which multiple diseases, such as hyperglycemia, hypertension, hyperlipidemia, and obesity, occur together in one individual [1]. Complications of metabolic syndrome may increase the incidence of cardiovascular diseases [2], and obstructive sleep apnea [3] or fatty liver disease [4] may also occur. It is known that the occurrence or prognosis of colorectal cancer [5], breast cancer [6], endometrial cancer [7, 8], and prostate cancer [9] is closely related to the constituents of metabolic syndrome [10]. Therefore, predicting the group at high risk for metabolic syndrome and actively preventing metabolic syndrome are essential for health care. The most common cause of metabolic syndrome has been presumed to be abdominal obesity [11]. In recent years, however, the need to consider nonobese metabolic syndrome has received attention [12]. Unlike obese metabolic syndrome, for which body weight reductions can decrease the risk and which has received much attention in health care, nonobese metabolic syndrome has no common cause, such as obesity. Without a special test, it is impossible to detect or suspect metabolic syndrome in nonobese individuals. In the nonobese metabolic syndrome population, the perception of health risks is relatively low and may be a blind spot of health care. Genetic studies of metabolic syndrome have reported a number of single nucleotide polymorphisms (SNPs) [13–20] that are known to be closely related to clinical factors, such as aging [21], sex [22], abdominal obesity [11], physical activity [23], alcohol consumption [24], and smoking [25]. However, no model has been published that combines these clinical and genetic factors in a metabolic syndrome prediction model. In this study, we constructed a model to predict metabolic syndrome in nonobese people using machine learning algorithms with factors such as age, sex, environmental factors, and lifestyle habits as well as genetic predisposition factors, such as SNPs, and evaluated the performance of the model.
Methods
Study population
We retrospectively used the Gene-Environmental Interaction and Phenotype (GENIE) database for Koreans; these data were collected from 10,349 healthy individuals who visited Seoul National University Hospital Gangnam Center for a comprehensive health check-up and consented to have their specimens included in a biospecimen repository. The program for comprehensive health check-ups and the GENIE database is described in another paper [26]. Briefly, blood pressure, waist circumference, height, and weight information were collected through anthropometric measurements during a health screening, and information on age, smoking, alcohol, exercise, and drug use was collected through interviews. After at least 10 hours of fasting, peripheral blood samples were obtained from all patients to determine the levels of fasting glucose, triglycerides, high-density lipopolysaccharide (HDL) cholesterol, and DNA samples were collected from the remaining blood. SNP genotyping was performed by an Affymetrix Axiom KORV1.1-96 Array (Thermo Fisher Scientific, Santa Clara, CA, USA) at DNA Link Inc. (Seoul, Korea).
Ethics statement
The Institutional Review Board of the Seoul National University Hospital approved this study protocol (IRB number H-1807-030-955), and informed consent was waived by the board. The study was conducted in accordance with the Declaration of Helsinki.
Clinical assessment and definitions
For this study, metabolic syndrome is defined according to the International Diabetes Federation’s criteria for the South Asian ethnic group [27], that is, the presence of at least 3 of the following metabolic risk factors: increased waist circumference (males ≥ 90 cm; females ≥ 80 cm); elevated blood pressure (≥130/85 mm Hg or the use of medications for hypertension); elevated fasting glucose levels (fasting glucose ≥ 100 mg/dL or the use of medications for hyperglycemia); elevated triglyceride levels (≥150 mg/dL); and reduced HDL cholesterol levels (males < 40 mg/dL, females < 50 mg/dL) or being under treatment for dyslipidemia. The metabolic score is the sum of the number of metabolic risk factors. Alcohol consumption was defined as yes when more than 140 g of alcohol was consumed per week, and smoking status was categorized as no or ex-smokers vs. current smoker. Exercise was grouped as not active vs. physically active. Physically active was defined as performing at least 150 minutes of vigorous or moderate intensity active per week. The study was conducted in nonobese individuals whose body mass index (BMI) was less than 25 kg/m2.
Genotyping and quality control
Genomic DNA was separated from venous blood samples, and 200 ng was genotyped using a Hybridization on Affymetrix Axiom KORV1.0-96 Array (Thermo Fisher Scientific). The PLINK program version 1.9 (https://www.cog-genomics.org/plink2) was used for the quality control process for the raw genotype data, resulting in a total of 586,730 SNPs to be used. SNPs with case and control minor allele frequencies less than 1%, case or control call rates less than 95% or a significant deviation from Hardy–Weinberg equilibrium in the controls (p < 0.0001) were excluded.
SNP selection for analysis
To design a model for predicting metabolic syndrome in the nonobese population, we selected the SNPs in two ways. In the first way, we used the genome-wide association study (GWAS) catalog database. We extracted the SNP list from the GWAS Catalog with keywords such as “metabolic syndrome,” “obesity,” and “adipose tissue.” For the extracted SNPs, we used SNPs that were included among the SNPs of the Affymetrix Axiom KORV1.0-96 Array (Affymetrix, Santa Clara, CA, USA) and had a p-value of less than 0.01 in the case control study for metabolic syndrome in our nonobese population. In the second way, we performed a GWAS study for metabolic syndrome in our nonobese population and selected the SNPs with p-values that passed the Bonferroni-corrected threshold (p < 8.52 × 10−8). We included all the SNPs selected using both ways to design the algorithm.
Prediction model design by machine learning tools
For the nonobese population (BMI < 25 kg/m2) population, the clinical information (age, sex, BMI, smoking history, alcohol consumption history, and exercise) and SNPs selected as described above (finally, 10 SNPs were selected: rs3764261, rs247617, rs2266788, rs964184, rs10830963, rs1260326, rs10830962, rs1883025, rs1919128, and rs11757661) were used to perform five types of machine learning analysis, multilayer perceptron (MLP) [28], naïve Bayes classification (NB) [29], random forest classification (RF) [30], decision trees classification (J48) [31], and support vector machine classification (SVM) [32], to predict metabolic syndrome. The additive model was used for genotype data used. The total population was divided into sets in a 7:3 ratio for the training set, which was used to develop the model, relative to the test set, which was used to validate the resulting model. The performance of the model was evaluated according to accuracy, specificity, sensitivity, F1 score, and the balanced classification rate. Model A was designed with only clinical information, and model B also included genetic information (information about the 10 SNPs). The machine learning analysis was conducted by Weka (Waikato Environment for Knowledge Analysis; University of Waikato, Hamilton, New Zealand). All analyses were two-tailed, and p-values < 0.05 were considered statistically significant. Statistical tests were performed using PLINK version 1.9 (https://www.cog-genomics.org/plink2), R statistical software (version 3.4.4) was used for statistical analyses, and p-values less than 0.05 were considered significant. The study outline is demonstrated in Fig. 1.
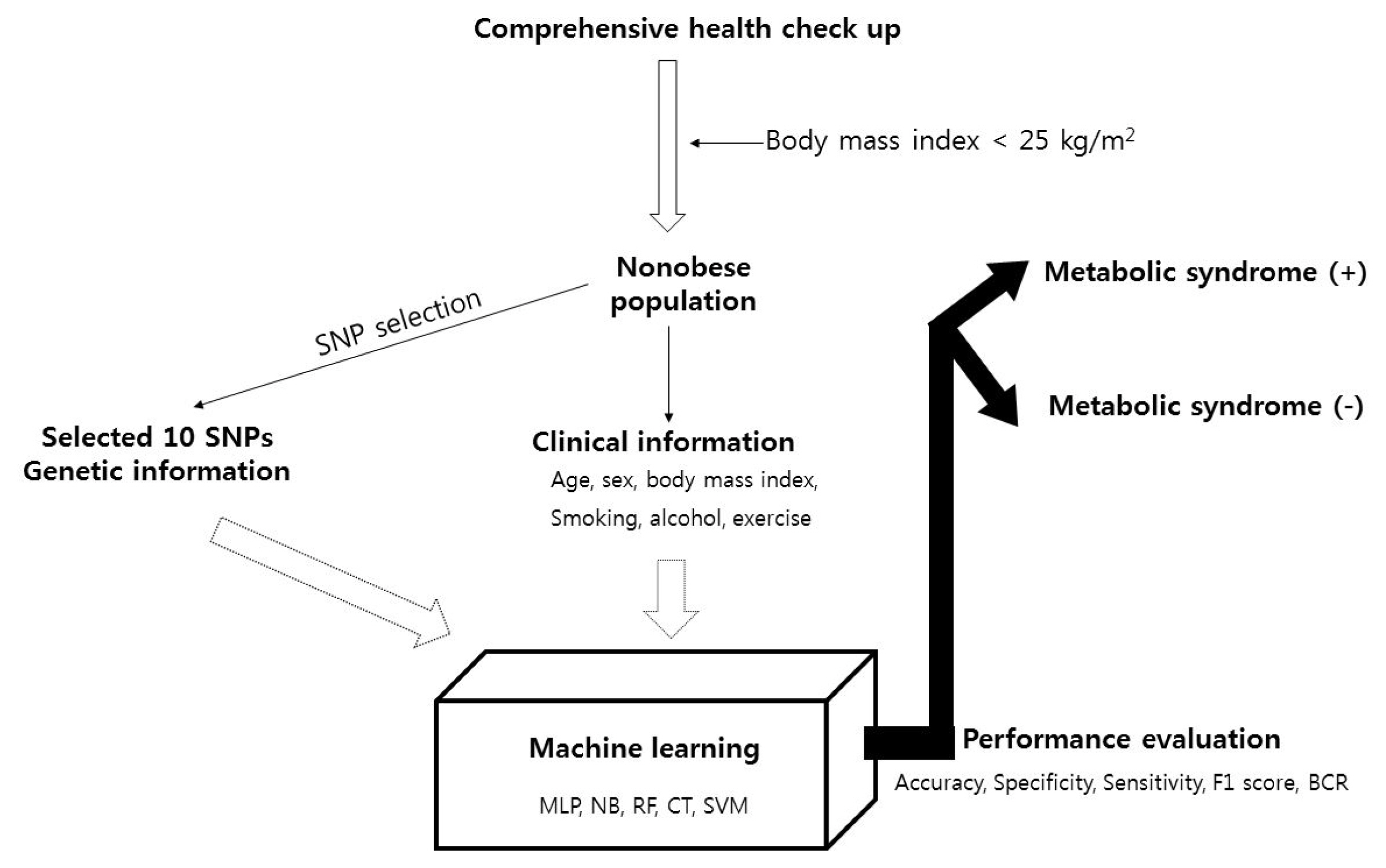
Study flow pipeline. SNP, single nucleotide polymorphism; MLP, multilayer perceptron; NB, naïve Bayes classification; RF, random forest classification; CT, decision tree classification; SVM, support vector machine classification; BCR, balanced classification rate.
Statistical analysis
For the GWAS, logistic regression analyses were used, controlling for sex as a covariate in the additive model. The performance was compared between model A (clinical data input only) and model B (clinical data + genetic data input) by drawing the receiver operating characteristic (ROC) curve and comparing the area under the curve confusion matrix. Statistical tests were performed using PLINK version 1.9 (https://www.cog-genomics.org/plink2), SAS 9.1 (SAS Institute Inc., Cary, NC, USA) and R 3.2.2 (R Development Core Team; R Foundation for Statistical Computing, Vienna, Austria).
Results
Study population characteristics
The 10,349 participants included 7,502 nonobese individuals. Metabolic syndrome was observed in 647 (8.6%) persons. The nonobese individuals were grouped into a training set (n = 5,251) and a test set (n = 2,251), and the baseline characteristics are shown in Table 1. Age, sex, BMI, smoking status, alcohol consumption status, and exercise status information were input into model A, and SNP information was additionally input into model B. The SNP information is described in Table 2.
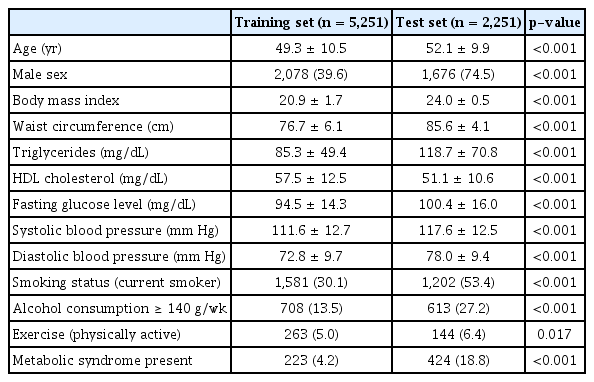
Demographic features of the training and test set populations

Information on the SNPs used in the algorithm
Overall comparison of the various machine learning tools
We used six machine learning methods, namely, MLP, NB, RF, decision tree classification, and SVM. Table 3 summarizes the performance of each model obtained with the various machine learning tools in the training and test sets. The purpose of generating our models is to provide a warning for a nonobese person who has an increased risk for metabolic syndrome. Therefore, we evaluated the sensitivity of the designed model. NB showed the best sensitivity, 0.38 for model A and 0.42 for model B. The specificity of NB was 0.79 for model A and 0.80 for model B.

Performance comparison among respective machine learning algorithms for predicting metabolic syndrome presence
Performance comparison between model A and model B
Via the area under the ROC curve (AUC), we compared the performance of model A and model B obtained with NB. Model B (AUC = 0.69), for which the input factors were the SNP information in addition to the factors used in model A, showed better performance than model A (AUC = 0.65), for which the input factors were age, sex, BMI, smoking status, alcohol consumption status, and exercise status.
Discussion
This study designed a predictive model for metabolic syndrome in nonobese people through machine learning using clinical information and polymorphism information obtained at a health screening. Among the various machine learning methods, NB showed the best performance, and the prediction model that included genetic information showed better performance than the prediction model designed with only clinical data.
It has been reported that people with metabolic syndrome have a 5-fold increased risk of developing type 2 diabetes mellitus, a 3-fold increased risk of developing cardiovascular disease [1], and increased cancer risk and cancer-related mortality [5–9].
Therefore, predicting the population with a high risk for metabolic syndrome and actively intervening with these individuals are very important for promoting health. Obesity is the most common risk factor for metabolic syndrome. Obesity is known to be associated with complications such as diabetes, hypertension, and cardiovascular disease [33, 34]. Obesity is clinically evident, so obese people can recognize the risk and prevent metabolic syndrome from occurring by undergoing aggressive weight loss efforts. However, metabolic disturbance can also occur in nonobese people. One cohort study reported that reduced inflammatory status, which is a metabolic syndrome pathogenesis, is observed in nonobese patients as well as obese patients [35, 36]. The problem for these nonobese patients is that without a specific biochemical test, these individuals do not know if they have developed metabolic syndrome and that they do not know if they are at risk for metabolic syndrome. The prevalence of undiagnosed metabolic syndrome in people with normal BMI is reported to be 5.2%–8.9% [37]. Therefore, predicting these factors plays a very important role in health care. To increase the predictive power in this group, we made a prediction model including genetic factors as well as clinical factors and performed analysis through various kinds of machine learning. Naïve Bayes classification showed the best performance.
The naïve Bayesian classifier (NBC) is a powerful probabilistic model that has been applied in various medical studies [38, 39]. The superiority of the NBC is that it takes all information into account to reach a decision, which is natural way for physicians to make diagnostic and prognostic decisions [40].
This study has the following limitations. First, only Korean individuals were included. Therefore, for generalization to other ethnicities, it is necessary to expand the study to include other ethnicities as well. Second, although the naïve Bayesian algorithm has the best performance, its sensitivity of 0.42 is not sufficient.
In future studies, it is necessary to improve performance by applying a deep learning algorithm.
The superiority of this study is as follows. First, we constructed a prediction model by integrating clinical information, environmental factors, and genetic information. Genetic studies of metabolic syndrome have been reported mostly for SNPs and are clinically known to be caused by several environmental factors. However, no method or algorithms have been published for integrating big data information, which is the result of these individual studies, into a metabolic syndrome prediction model for nonobese populations. In metabolic syndrome, not only the genetic polymorphism of SNPs but also factors such as age, sex, environmental factors, and lifestyle habits are all involved, and the presence of these genetic and clinical factors controls the development of metabolic syndrome. In addition, although the GWASs used in the existing SNP analysis found SNPs that are candidate markers for a number of metabolic disorders, all of the studies considered individual SNPs, and no studies have analyzed SNPs in an integrated manner. Second, machine learning was used to build predictive models. The traditional construction of models by statistical methods is mostly conducted with only clinical information, and factors in the prediction model that have borderline influence are often deleted during the model design process. Additionally, for the traditional models, it is difficult to reflect all the associations between the factors. In the case of machine learning, data and factors of borderline significance can be considered in the analysis without overlooking data that are not well known. Third, model A in our study, which is designed only using clinical information, itself has useful value in the clinical field. Model A used information such as age, sex, body mass index, smoking, alcohol consumption, and exercise. This information can be obtained easily without any special medical inspection. If a nonobese person inputs their information into the algorithms, they can be alerted to their risk of metabolic syndrome and take active interventions to prevent complications. This application can be performed by the nonobsese person himself or herself without the help of a medical specialist. After conducting a replication study in another population set and improving the performance of this model, we are planning to make it accessible as a website in the future.
In this study, a prediction model was constructed by integrating clinical information, environmental factors, and genetic information. The purpose of this study is to provide a prediction model for metabolic syndrome that is more predictive of metabolic syndrome than previous models, by using clinical and genetic markers related to metabolic syndrome specifically in a nonobese population. Using this prediction model, we could predict the group of nonobese individuals who have a high risk of developing metabolic syndrome. For the individuals in this group who previously did not feel a need to use healthcare services and were not concerned about metabolic syndrome, we could encourage them to receive health checks and modify their lifestyle to include preventive habits. This process would save them from cardiovascular disease and several cancers that are complications of metabolic syndrome. This can be used as part of a more comprehensive health care method.
Acknowledgments
This work was supported by the Technology Innovation Program (10050154, Business Model Development for Personalized Medicine Based on Integrated Genome and Clinical Information) funded by the Ministry of Trade, Industry & Energy (MI, Korea).
Notes
Authors’ contribution:
Conceptualization: SHC, EKC, HR, ES, JEL
Data curation: EKC, SWO
Formal analysis: EKC, ES, SL
Methodology: EKC, ES, SL
Software: ES, SL, JEL
Investigation: SHC, EKC, HR, SWO
Writing – original draft preparation: EKC
Writing – review and editing: SHC, SWO
Approval of final manuscript: all authors.
Conflict of interest
No potential conflicts of interest relevant to this article was reported.