Introduction
Dyslipidemia is an important etiological factor in the development of cardiovascular disease (CVD), which is the leading cause of deaths for adults. Dyslipidemia is mainly characterized by elevated levels of triglycerides (TGs), increased low-density lipoprotein cholesterol (LDL-C), and reduced high-density lipoprotein cholesterol (HDL-C) [1].
In the past few years, genome-wide association studies (GWASs) and meta-analyses have identified common genetic variants that contribute to blood lipid phenotypes in Caucasian-based populations [2-8]. In addition, we have convincingly mapped 16 loci for major lipoprotein concentrations (TG, HDL-C, and LDL-C) in a two-stage association study in individuals of East Asian ancestry [9].
Given the growing global epidemic of metabolic syndrome, including obesity and type 2 diabetes (T2D), lipoprotein metabolism disorders have become an important health problem in adulthood but also have emerged as an increasingly prevalent risk factor in childhood [10]. Although many GWASs and meta-analyses have provided susceptibility genes or loci for lipid-related traits from multiple large population-based cohorts of adults, it is of great importance to evaluate genetic predisposition at an early age. However, little is known about their genetic effects in a younger population. Moreover, most identified variants have shown modest effects and have explained only a small proportion of heritable components for disease risk [11]. Nevertheless, when multiple genetic markers are considered together, literature-based genetic risk scores might be useful in improving the identification of the genetic contribution in those at high risk of disease [12-14]. Therefore, the aim of this study was to consolidate the associations of GWAS-based candidate variants with blood lipid concentrations in a childhood obesity study and to evaluate genetic risk scores (GRS) for lipid-related risk phenotypes.
Methods
Study subjects
Korean Association Resource (KARE) study was collected through the Korean Genome Epidemiologic Study project - in total, 10,038 people, 40-69 years old, living in Ansung and Ansan, from 2001-2002. For more information, the study has already been reported [9, 15]. The Health Examinee cohort (HEXA) shared project is a community-based epidemiological cohort of 1,200,000 subjects (aged, 40-69) who were recruited for baseline examination from 2004 to 2009. To share the controls, 4,302 subjects were randomly selected to participate between 2006 and 2007. The BioBank Japan study was approved by the ethical committees in the Institute of Medical Science, the University of Tokyo, and the Center for Genomic Medicine, RIKEN. Subjects for the Health2 cohorts for the replication study were selected from another community-based cohort sample provided by the Health2 study, as described previously [15]. We examined 7,861 selected from the 8,500 participants (aged, 40-69). The students aged 9 and 12 years were recruited from Gwacheon City and Gyeonggi Province between April and June 2010. This study was conducted as part of the Korean Children-Adolescents Study (KoCAS), which has been monitored yearly since their entry into elementary school at age 7 in Gwacheon City or fourth grade at age 10 in Seoul and Gyeonggi Province, Korea. Subjects who were enrolled in a specific diet program or were taking any medications known to affect appetite were excluded from the study. The study protocol was approved by the institutional review board of Seoul-Paik Hospital, Inje University, and the Korea Center for Disease Control and Prevention. Informed consent was obtained from the children's parents.
Genotyping
KARE samples were genotyped using Affymetrix Genome-Wide Human SNP array 5.0 (Affymetrix, Santa Clara, CA, USA) and processed by Bayesian Robust Linear Modeling using the Mahalanobis Distance (BRLMM) genotyping algorithm [16]. The HEXA shared sample was genotyped using Affymetrix Genome-Wide Human SNP array 6.0 and processed with the Birdseed Genotyping Algorithm [17]. The BioBank Japan study was genotyped using the Illumina Human610-Quad BeadChip (Illumina Inc., San Diego, CA, USA). A childhood obesity study was genotyped using the Illumina Omni1-Quad BeadChip. Individuals were excluded as follows: genotyping call rate, sex inconsistency, heterozygosity, identity-by-state value, and any kinds of tumor. For more information, the study has been reported [15].
For the replication study in Health2 (7,861), we performed a genotype assay using the TaqMan reaction for four single nucleotide polymorphisms (SNPs) (rs2074356, rs16940212, rs12708980, rs599839) and the GoldenGate assay (Illumina Inc.) for nine SNPs (rs780092, rs10503669, rs2001945, rs603446, rs12686004, rs11216126, rs12229654, rs519113, rs12654264, rs2738446). To analyze the quality control, we conducted duplicate genotyping using 1-2.5% of samples. For further association analyses, concordance rates were satisfied with duplicates of over 99% and a genotype success rate of over 98%.
SNP imputation
In each GWAS data point, imputation analysis was performed using the IMPUTE reference HapMap Asian (Japanese [JPT]/Han Chinese [CHB]) population panel, based on NCBI build 36 and dbSNP build 129. Of these, in each cohort, we dropped SNPs with a posterior probability score < 0.90, high genotype information content (info < 0.5), Hardy-Weinberg equilibrium (HWE) (p < 1 × 10-7), SNP missing rate > 0.1, and minor allele frequency (MAF) < 0.01. In the former analysis, only imputed SNPs that satisfied the genomewide SNP quality control criteria were considered.
Association analysis
In performing the association tests, SNPs were analyzed with PLINK (http://pngu.mgh.harvard.edu/~purcell/plink/) and SAS version 9.1 (SAS institute Inc., Cary, NC, USA). Individuals who were on lipid-lowering therapy and hypertensive medications were excluded for dyslipidemia-related phenotypes, such as TG, HDL-C, and LDL-C. LDL-C concentrations were calculated with Friedewald's formula [18]. Missing values were assigned for individuals with TG over 400 mg/dL. The dyslipidemia-related phenotypes were tested by multivariate linear regression analysis in an additive genetic model (1-d.f.), including age, sex, and recruitment area as covariates. TG and HDL-C were transformed prior to analysis using natural log transformation to remove skewing. LDL-C was normally distributed, and no transformations were required. A GRS was examined using multivariate linear regression analysis, adjusting for age, sex, and recruitment area.
Results
The clinical characteristics and statistics of the variables for each study sample are described in Table 1. Our previous large-scale GWAS identified 9 novel and 24 known genetic loci influencing metabolic traits in East Asians [9]. In an attempt to determine whether well-established lipid-related variants contribute to significant and reproducible genetic factors for susceptibility to blood lipid concentrations in a childhood obesity study, we first examined the associations between individual genetic variants and lipid-related phenotypes using linear regression analysis.
Of these 16 SNPs for blood lipid traits, rs10503669 in LPL (genotyped SNP in a childhood obesity study) was significantly associated with TG and HDL-C, respectively. In addition, rs16940212 in LIPC (linkage disequilibrium-based proxy SNP) was associated with HDL-C (Table 2). The direction of these associations was consistent with our previous GWAS [9].
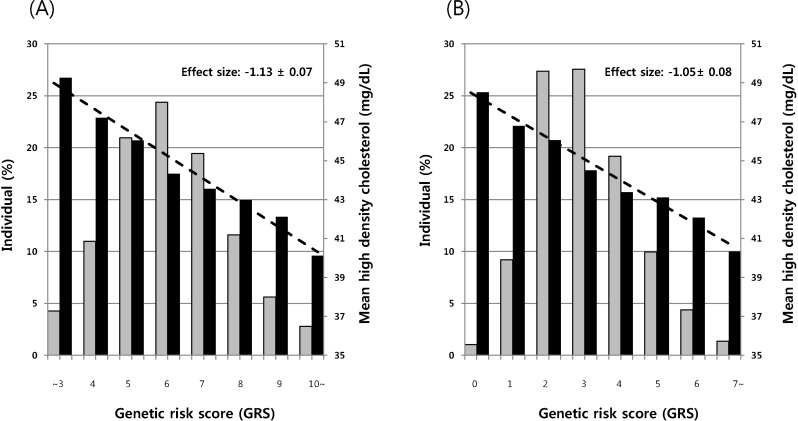
Having two loci (rs10503669 at LPL and rs16940212 at LIPC) showing the strongest association with TG and HDL-C, we next investigated whether the cumulative allelic dosage of risk alleles contributes to the quantitative variation of lipoprotein concentrations in the KARE study using a method of calculating a GRS. We evaluated the joint effects of the best-associated SNPs at the two loci showing evidence of association with HDL-C (rs10503669 at LPL and rs16940212 at LIPC). We calculated a GRS, representing the sum of the risk alleles, and observed that increasing GRS was significantly associated with decreased HDL-C (effect size, -1.13 ± 0.07) compared to SNP combinations without two risk variants (Fig. 1). In addition, a positive correlation was observed between allelic dosage score and risk allele (rs10503669 at LPL) for high TG levels (effect size, 10.89 ± 0.84) (Fig. 2).
Discussion
Blood lipid levels are an important etiological contributor to CVD. CVD is the leading cause of death among individuals with T2D, in which lipid abnormalities are characterized by hypertriglyceridemia, reduced levels of HDL-C, and elevated levels of LDL-C. These lipid-related traits, including ~14-54% for TG, ~34-42% for HDL-C, and ~28-50% for LDL-C, are highly heritable in familial T2D or diabetic patients [19, 20]. These estimates indicate that genetic variants play important roles in explaining inter-individual variations in blood lipid levels.
Although systematic reviews have reported relationships between childhood obesity and adult CVD risk [21, 22], there is not a shred of evidence that blood lipid status in adults is an independent or dependent risk factor in a childhood obesity group. Early childhood obesity might be the best time for dyslipidemia intervention, including screening, early detection, and management. The aim of this study was to consolidate the associations of 16 GWAS-based candidate variants with blood lipid concentrations across the lifespan.
In GWAS-based candidate approaches, the well-known LPL gene was significantly associated with low TG and high HDL-C levels in a childhood obesity study, respectively. This finding is well matched to the negative correlation between blood TG and HDL-C concentrations [23]. In addition, the LIPC gene was further observed in decreased HDL-C. In analyses of the joint effects of these variants, we found that GRSs on the two risk alleles (rs10503669 at LPL and rs16940212 at LIPC) were associated with a cumulative effect of TG and HDL-C levels. However, these facts indicate that currently identified risk variants might have low discriminatory ability and modest genetic contribution to disease prediction [24].
Lipoprotein lipase (LPL) plays an important role in lipid metabolism by hydrolyzing TGs of circulating chylomicrons and very low-density lipoproteins. In addition, LPL is expressed in the brain regions that are functionally relevant to learning, memory, and other cognitive functions. Many GWASs and meta-analyses have shown that variations in the well-known LPL gene for multiple lipid-related traits are implicated in multiethnic populations [2, 3, 9, 25-28]. An increasing number of studies have suggested an association of LPL gene variants with the risk of cerebrovascular as well as CVD [29]. Recent genome-wide investigations identified schizophrenia-associated loci in the chromosome 8p22 region, including LPL [30-32]. It was suggested that LPL is an attractive candidate gene that might be involved in the potential role of lipid metabolism in schizophrenia. Stages of early childhood development can be taken into account when considering a diagnosis of mental illness [33].
Hepatic lipase (LIPC) gene encodes hepatic triglyceride lipase, which is expressed in liver. LIPC has a dual function as a triglyceride hydrolase and ligand/bridging factor for receptor-mediated lipoprotein uptake. A GWAS has identified a possible role of LIPC in advanced age-related macular degeneration (AMD) [34]. AMD is an eye condition affecting the central part of the retina. Although a condition that is commonly associated with the elderly, macular degeneration affects younger people through a rare inherited condition [35]. Based on a lack of direct relationships between HDL-C and AMD risk, the LIPC association may not be the result of an effect on HDL-C levels, but it could represent a pleiotropic effect as a functional component, such as a lipoprotein transporter, underlying the biological mechanisms involving the cholesterol pathway.
Taken together, our findings demonstrate that the genetic architecture of circulating lipid levels (TG and HDL-C) overlap to a large extent in childhood as well as in adulthood. A genetic risk assessment by incorporating two risk alleles suggests encouraging evidence that identified genetic risk variants for lipid phenotypes have cumulative effects on lipid concentrations. Post-GWAS functional characterization of these variants is further required to elucidate the pathophysiological role and biological mechanisms.