Introduction
A multilevel model has gained popularity as a practical and essential analysis tool in various fields such as epidemiological research, public health research, and social or educational research [1ŌĆō6]. A specific study design involving multiple levels or nested structures results in a hierarchical structure and accompanies the application of multilevel modeling [1]. Multilevel data are often obtained as an incomplete dataset with missing components at any level of the data hierarchy. For example, in practice, a nesting of some hospitals and practices, which are also nested within larger health systems, can be ignored or unobserved in the health care study [7].
In practice, researchers in the field ignore a hierarchy within the data and prefer an ordinary least square regression model (OLS) that treats all observations as if they are measured at the same level [8ŌĆō12]. Alternatively, a two-level model is also commonly adopted by ignoring missing intermediate levels and accounting for only the top and bottom levels of hierarchy in multilevel data. However, the misleading hierarchy by ignoring intermediate or top levels may potentially impact the parameter estimation in multilevel analysis and has gained attention among researchers in recent research [13ŌĆō17].
To handle the missing issues, several studies proposed imputation methods to fill in the missing and create a complete dataset [15ŌĆō17]. However, imputation methods add more uncertainty to the parameter estimations and especially increase the complexity when the imputation is intertwined with the hierarchical structure of the data [15ŌĆō18]. In particular, it is difficult to handle the missing when a cluster is entirely missing or the cluster size is very small, and especially the missing values are in the explanatory variables. Alternatively, a single imputation can be considered. It is because it handles the practical issues in multilevel imputation, is simple to adapt, and preserves the design hierarchy of the multilevel data. In this study, we consider a multilevel linear mixed effect model (LMM) with a single imputation that was introduced in Sanders' study [19] for handling missing intermediate or top clusters in multilevel data. An LMM has been widely accepted to model the hierarchical structure in multilevel data and can account for the correlation among units nested within clusters. The method uses a single imputation that replaces the missing clusters by its nesting lower-level unitŌĆÖs measurements and considers as if each of the nesting lower-level unitŌĆÖs measurements is a single observation for missing clusters. As a result, a missing intermediate-level cluster is filled in containing only a singleton, resulting in a complete dataset [19]. However, to our best knowledge, no previous studies have examined and investigated the performance of an LMM with a single imputation and directly compared it with other models that ignore missing levels of nesting.
This study aims to evaluate the performance of a model considering all hierarchies, such as an LMM with single imputation, in three-level data and demonstrate that it outperforms other models that do not match the hierarchy of multilevel data. To do so, we compare three models in three-level hierarchical data with missing intermediate-level clusters. The first model is an OLS regression model, which is a single-level model ignoring any hierarchy in the data and treats all observations measured at the same level. Secondly, we consider a two-level LMM considering only level-1 and level-3 and discarding missing intermediate levels. The third model is a three-level LMM with a single imputation that involves all levels of the data hierarchy, so we can assume that the multilevel model matches the design hierarchy in the data by filling in a missing level-2 unit.
In this study, we apply and compare the three models to the Childhood to Adolescence Transition Study (CATS), a motivating case study of this work, in a three-level structure: school (level-3 unit), individual (level-2 unit), and repeated measures observed per individual (level-1 unit) with missing level-2 and level-3 units [20,21]. We also conduct a thorough simulation study by comparing the three models to examine the impact of ignorance of missing intermediate level on parameter estimation of three-level data analysis when the missing rate and the cluster sizes of level-2 and level-3 clusters vary.
Methods
Three-level linear mixed effect model
In the context of multilevel data analysis, a LMM is considered as an analysis model that accounts for correlation due to the hierarchical structure of the data. To establish background information on the analysis model for hierarchical structure data, especially for a three-level data structure, we develop a general notation and introduce a brief overview of a three-level model.
Let i be the index of the level-3 unit with size L (i=1,┬Ę┬Ę┬Ę,L), j be the index of the level-2 unit with size Mi (j=1,ŌĆ”,Mi), and k be the index of the level-1 unit with size Nij (k=1,ŌĆ”,Nij). We consider a three-level model, where a level-1 unit is nested within a level-2 unit that is also nested within a level-3 unit. Let yijk be the response variable for level-1 unit k in the level-2 unit j and level-3 unit i, xijk be the associated covariate variable observed at level-1, xij be the associated covariate variable at level-2, and xi be the associated covariate at level-3. Then a general three-level linear mixed effect model is:
(1)
where
e i j k ~ N ( 0 , Žā e 2 )
In this study, we assume that only the regression intercept varies across clusters and hence restrict our attention to a three-level random effect model with a random intercept for each level. It is the simplest type of linear mixed model for multilevel study, although we note that an extended model including random slope can be considered. We revisit this in the discussion. Considering a random effect model with random intercepts only, ╬▒11=vŌĆ▓ij=╬│11=uŌĆ▓i=0. Therefore, the model in Eq. (1) can be rewritten as
where ╬▓0(=╬│00) is the intercept, and ╬▓1(=╬│01),╬▓2(=╬▒01), and ╬▓3(=╬│10) are the slope coefficients for the fixed effects at level-3, level-2, and level-1, respectively. Considering random intercepts only in the model, we assume that level-3 and level-2 residuals, ui and vij, respectively, are multivariate normal with zero means and variances of
Žā u 2 Žā v 2 Žā e 2
The covariance structure of the response vector y=(y111,y112,ŌĆ”,yL,ML,NLM) is a block-diagonal covariance matrix given by
with an ith block-diagonal matrix of
G i = Žā e 2 I ( n i ) + Žā v 2 J ( n i )
Analysis of incomplete multilevel data using single imputation
To handle the missing level-2 units in a three-level hierarchical data, we adopt a single imputation method introduced in SandersŌĆÖ study [19] that replaces the missing clusters by its nesting lower-level unitŌĆÖs measurements and considers the imputed level-2 unit as a cluster containing a single observation. Specifically, it constructs imaginary level-2 clusters for level-1 measurements whose level-2 clusters were missing entirely. As a result, the single imputation method adds level-2 clusters as many as the number of level-1 units directly under the missing level-2 clusters. By applying the method, we can have a complete three-level dataset without any missing clusters at level-2 units, allowing us to apply a three-level model. The single imputation method allows us to preserve a hierarchical data structure in multilevel data analysis.
The motivating case study CATS has a three-level structure with the components of school, individual, and its repeated measures per individual, and some measurements at the individual level (level-2; academic numeracy score at baseline) were partially not observed and recorded as missing in the dataset. There were 22.4% missing academic numeracy scores at baseline at level-2, and they were filled in by single imputation that impute a corresponding academic numeracy score measured at level-1 to handle the components with missingness. In other words, we treated each level-1 unit within a missing level-2 unit is nested in a level-2 unit that only contains the level-1 unit itself [19].
Childhood to Adolescence Transition Study
Motivated by the case study of CATS, we focus on an analysis of the simulated data mimicking the CATS data [21]. The CATS is a longitudinal cohort study collected through multiple waves, and it collects mental health to investigate the effect of early depressive symptoms on academic outcomes in children from puberty through adolescence. More details about the data collection and study protocol can be found in Mundy et al. [20].
The simulated data mimicking the CATS have a three-level hierarchical structure. Individuals are nested within schools, and repeated measures within individuals were collected. The data consist of demographic, educational, and social outcomes as well as mental health outcomes for the CATS study: depressive symptoms, National Assessment Programme ŌĆō Literacy and Numeracy results (NAPLAN) academic numeracy score, socio-economic status, age, and sex are collected for the study [21].
The NAPLAN numeracy score is an outcome of interest and is observed at level 2 at wave 1 (potential baseline) and at level 1 in the following waves with missing cases. As we are interested in a case where missingness happens at level-2 only, we discard cases where the NAPLAN numeracy score has missingness at level-1, and the size of data that we used is N = 2,592. The data are unbalanced as the size of level-2 differs, and the number of level-1 units within a level-2 unit varies across individual. The dataset has 163 schools; 54 of 163 schools have a single individual with a single measurement per individual, and the other 109 schools have multiple individuals with a different number of repeated measures. There were 1,142 individuals in the data, and 256 of 1,142 (22.4%) NAPLAN numeracy scores at the individual level are missing.
Simulation data
We conducted a simulation study to evaluate the performance of a three-level LMM with single imputation. In the simulation, we considered complete three-level data sets and incomplete data with various missing rates of level-2 clusters (Table 1) and compared the performance of the three-level LMM with single imputation with those of a single-level model and 2-level LMM.
We generated complete data sets without missing subjected to the model in Eq. (2), where we assumed the fixed coefficients of ╬▓0=0.5, ╬▓1=╬▓2=╬▓3=0.3, the random effects at level-2 and level-3 of
u i ~ N ( 0 , Žā u 2 ) v i j ~ N ( 0 , Žā v 2 ) e i j k ~ N ( 0 , Žā e 2 )
To evaluate the performance of the three-level LMM in the presence of missingness at the level-2 units, we generated missingness from each of the complete 3-level data sets (Table 1). We set the complete data to be missing in M level-2 clusters and its related variables such as xij. The missing data rate in level-2 clusters was set to 10, 25, 50, and 75% of M level-2 clusters.
Results
Childhood to Adolescence Transition Study
We use three analysis models to determine the effect of ignorance of hidden levels in the hierarchically structured CATS data: (1) a single-level model (ordinary least square regression) that completely ignores the structure of the hierarchy and treats the data collected at level-1 only (M1), (2) a two-level LMM with a random effect for school (level-3) only and ignoring an individual (level-2) random effect (M2), and (3) a three-level LMM with single imputation considering all levels of hierarchy in the CATS study units (M3). The LMMs we fit for M2 and M3 only have random intercepts, and random slopes are not considered in the data analysis. Tables 2 and 3 report estimates of the fixed and random effects, respectively, across the three models.
Table 2 presents estimated coefficients of fixed effects in each model, and Table 3 presents the estimated variance components of random effects and residuals. Note that M2 has one random effect at school and M3 has two random effects at school and individual.
Based on a significance level of 5%, depressive symptoms appeared to be significantly meaningful in supporting the effect of mental health on academic outcomes in children from puberty through adolescence across the three models (p < 0.001). Age and NAPLAN numeracy scores observed at baseline were meaningful covariates for explaining the relationship with academic outcome in addition to the mental health outcome. That is, when children are young, have fewer depressive symptoms, and higher NAPLAN numeracy scores at baseline, academic outcomes are likely to be higher. Noticeably, the estimated coefficients of the important covariates do not differ much across the three analysis models.
Table 3 presents the estimated variance components of random effects and residuals in the multilevel data across the three analysis models with different hierarchy levels. The estimated residual variance quantifies the variation within repeated measures and decreases when random effects are included in the analysis model (M2 and M3). The estimated variance components of the random effects explain variations across schools and individuals that were not explained by M1, and the sum of the estimated variance components in M3 is larger than in M2. This implies that M3 captures more unexplained variation in the hierarchical structure data, especially the variation among individuals, which cannot be ignorable. Hence, the analysis without accounting for the variance among the unobserved level of nesting units in data analysis resulted in a larger estimation of the residual variance as shown in Table 3. It might lead to an inaccurate estimation of the total variation in the multilevel data.
Simulation data
Considering 30 scenarios (Table 1), we applied a single-level model (M1) and 2-level LMM (M2) and 3-level LMM with single imputation (M3). M1 and M2 estimate four fixed coefficients, and the standard deviation
Žā e 2 Žā v 2 Žā u 2
We expected that M3 performed well in the presence of unobserved level-2 clusters, whereas M2 would poorly estimate the coefficient ╬▓2 of the level-2 associated covariate with missing clusters since M2 ignored the level-2 clusters and partially incorporated the date structure of level-1 and level-3 clusters. Since the M1 did not consider the hierarchical data structure, we expected that it poorly estimated ╬▓1 and ╬▓2.
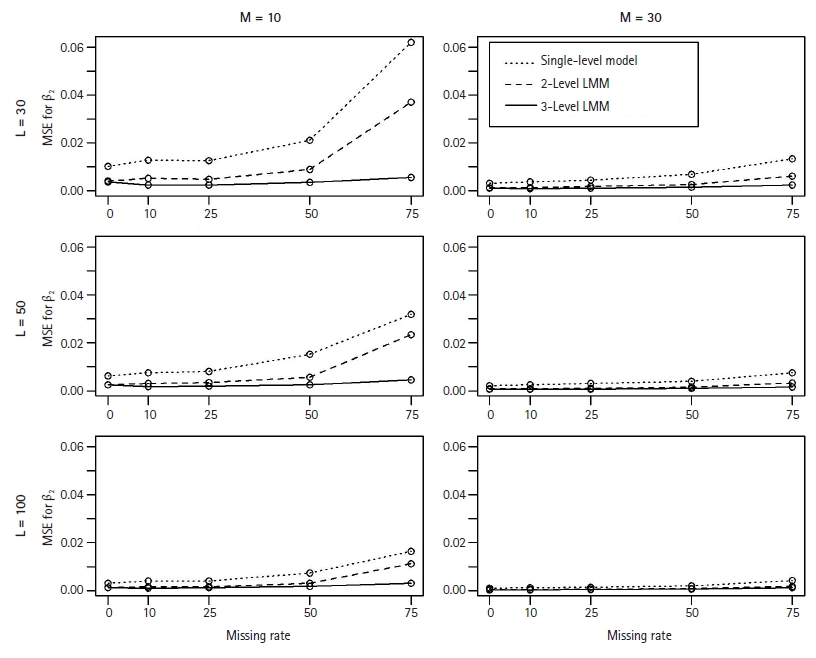
In general, the M3 performed well and better estimated the fixed coefficients in Eq. (2) than the M1 and M2 models. As expected, in particular, we observed that the M1 and M2 models poorly estimated the coefficient ╬▓2 of the level-2 associated covariate with missing clusters. Figs. 1 and 2 show the MSEs and the coverage probabilities for ╬▓2, respectively, and compared those values by the three models. The MSEs by the M3 ranged from 0.00039 to 0.00557, while those by the M1 and M2 were 0.0011ŌĆō0.0639 and 0.0004ŌĆō0.037, respectively (Fig. 1). The coverage probabilities for ╬▓2 by the M3 were approximately 0.814ŌĆō0.964 (Fig. 2). The M1 and M2 models did poorly estimate ╬▓2 and their coverage probabilities low as 0.27ŌĆō0.406 and 0.392ŌĆō0.498, respectively (Fig. 2). The MSEs for ╬▓2 seemed to increase with the missing rate (Fig. 1); however, the coverage probabilities did not change as the missing rate increased.
We observed MSEs for ╬▓0, ╬▓1, and ╬▓3 similar to Fig. 1. The differences in MSEs among the three models were small, but M3 performed the best overall. Moreover, MSEs tended to increase with missing rates. Similar to Fig. 2, the coverage probabilities for ╬▓0 and ╬▓1 were around 0.95 from the M3, while we observed small coverage probabilities from M1 (e.g., 0.06ŌĆō0.302 for ╬▓1) and comparable coverage probabilities from M2 (e.g., 0.926ŌĆō0.96 for ╬▓1). The three models yielded similar coverage probabilities for ╬▓3.
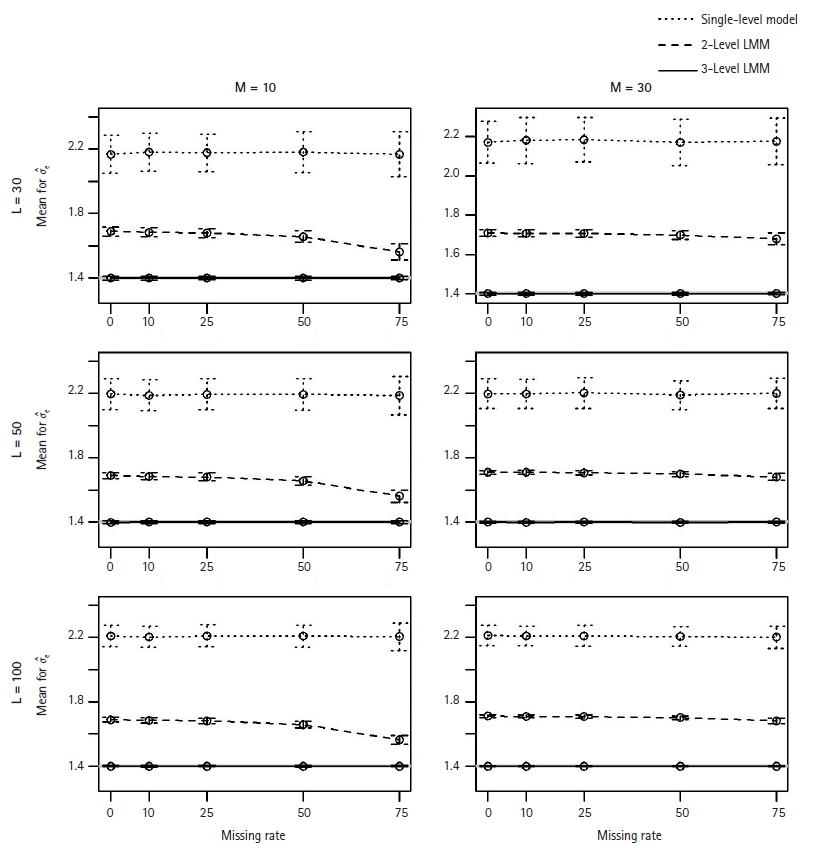
The three models contain different variance components. M3 can estimate the three standard deviations, Žāu, Žāv and Žāe. However, M2 does not estimate the variance
Žā v 2 Žā e 2
Figs. 3 and 4 show that the MSEs and coverage probabilities for Žāv from M3 worsened as the missing rate increased for each case of L and M values. At the same missing rate, the larger value of M, the better the coverage. However, more level-3 clusters did not improve MSE and coverage probability. This is because each level-3 cluster contains unobserved level-2 clusters, and hence the number of unobserved level-2 clusters increases as L increases.
We observed that the estimates for Žāu and Žāe from M1 were unbiased with small MSEs and their coverage probabilities were close to the nominal level of 95% (0.918ŌĆō0.96 for Žāu; 0.936ŌĆō0.974 for Žāe). However, the coverage probabilities of M1 and M2 models were very low (e.g., 0ŌĆō0.344 for Žāu and 0ŌĆō0.006 for Žāe from the 2-level model), and Žāu and Žāe were overestimated by M1 and M2 models (see Fig. 5 for the average estimates for Žāe).
Discussion
In this study, we investigated the effect of missing intermediate level of the hierarchical structure data with varying missing rates, as well as the consequence of ignorance of the level of nesting on the parameter estimation of multilevel analysis. Since missing level-2 units are imputed by the nested level-1 unitŌĆÖs measurement, the intermediate-level unit has a single observation per unit, and the data can be considered sparse. We compared three models with different levels of hierarchy across varying missing rates at the intermediate-level and various cluster sizes in the top- and intermediate-level clusters. We observed that the three-level LMM with single imputation showed a better performance compared to the other two models, which ignore higher levels of nesting in terms of MSE and coverage. Moreover, lower-level variance components were overestimated, indicating that variance components are affected by ignorance of the intermediate level.
We considered a random effect model for the 2-level and 3-level linear mixed effect models in the simulation study and data application for brevity, and it can be expanded to consider a random slope model and/or interaction terms. However, it requires caution to generalize the model analysis to be more complex because we have a large number of intermediate-level clusters with a single observation, and such sparse clusters might lead to biased estimates in random slope estimation [22]. Also, we have incomplete variables for intermediate-level units. An imputation requires careful caution when incomplete explanatory variables with a random slope and/or interaction terms exist in the model because they might lead to invalid estimates [10].
Furthermore, we used a three-level LMM with single imputation that replaces the missing by the nesting lower-level unitŌĆÖs measurements and considering that a single observation is measured per intermediate-level unit. As a future study, other imputation methods for multilevel data can be considered and compared their performances with an approach studied in this work. In practice, it is common that level-1 and level-2 units are both missing, and in such case, the imputation method, such as a multiple imputation handling multiple levelŌĆÖs missingness, should be considered.