Human Population Admixture in Asia
Article information
Abstract
Genetic admixture in human, the result of inter-marriage among people from different well-differentiated populations, has been extensively studied in the New World, where European colonization brought contact between peoples of Europe, Africa, and Asia and the Amerindian populations. In Asia, genetic admixing has been also prevalent among previously separated human populations. However, studies on admixed populations in Asia have been largely underrepresented in similar efforts in the New World. Here, I will provide an overview of population genomic studies that have been published to date on human admixture in Asia, focusing on population structure and population history.
Introduction
Before I review the recent research progress on Asian admixed populations, I would like to first give some overview of the background of admixture studies, especially in the context of population genomics, since admixture analysis is only feasible when individual genomic data are available.
Genetic Structure of Admixed Populations
Human migration resulted in population differentiation, and many populations, especially those living in different continents, have been isolated for quite a long time. However, subsequent migrations that have occurred over the past millennia have resulted in gene flow between previously separated human subpopulations. This has been a common phenomenon throughout the history of modern humans, as previously isolated populations often come into contact through colonization and migration. As a result, admixed populations came into being when previously mutually isolated populations met and inter-married. It is important to conduct a full analysis of genetic structure and characterize the genetic make-up of admixed populations. On the one hand, this will shed light on human genetic history; on the other hand, increased population admixture influences genome heterozygosity, which in turn will affect phenotypes relevant to health; thus, genetic admixture has many implications in medical research.
Admixture Mapping
The estimation of genetic admixture in human populations has been used for a variety of purposes, ranging from the confirmation of historical events, such as population of the effects of other biological parameters, but the emphasis in early studies was on gene mapping of continuous traits. Admixture mapping is a method for localizing disease-causing genetic variants that differ in frequency across populations. This approach was proposed by McKeigue in 1998 [1]; it is based on the association of local chromosomal ancestry with the disease, to test for the linkage of the disease or trait with parental ancestry at each locus, defined as 0, 1, or 2 allele copies inherited from the ancestral populations. However, the idea of using genetic architecture in admixed genomes to locate disease-associated genes was actually first proposed by Rife in 1954 [2], although the original idea was to use the admixture linkage disequilibrium (ALD) generated in recently admixed human populations to assign the traits to linkage groups.
Admixture of populations often leads to extended linkage disequilibrium (LD), which could greatly facilitate the mapping of human disease genes [3-6]. Gene mapping by admixture linkage disequilibrium (MALD) has been shown to have special value theoretically [4, 7-14] and empirically [15-29]. MALD has received much attention recently [3, 5]. The initial attraction of MALD was its significantly increased extension of LD (or extended LD) in admixed populations, which requires far fewer markers in mapping disease genes. Previous studies predicted that MALD typically requires only 2,000-3,000 ancestry informative markers (AIMs) for a genomewide search [1, 16]. The utility of MALD depends upon how far LD extends over a chromosomal interval, which, in turn, dictates the spacing and number of markers required for a genomewide scan. Therefore, it is imperative to characterize the magnitude and extent of ALD in the admixed population in which MALD will be performed.
Stephens et al. [10] showed that ALD in African-Americans (AfAs) could exist up to 10 cM, even after 9 generations by simulation. Parra et al. [30] reported strong LD between the FY-null and AT3 loci, which are 22 cM apart on chromosome 1q22. Substantially extended LD in AfA populations were reported in several regions or chromosomes [31-33] using primarily short tandem repeat markers. Patterson et al. [12] showed that strong ALD extends to 17 cM on average in AfAs. Contrarily, it was also reported that the LD in AfA populations is shorter than or similar to those seen in non-admixed populations using single-nucleotide polymorphisms (SNPs)-detectable to about 44 kb or larger [34]. The contradicting observations might be due to the selection of the markers based on their allele frequency difference between the parental populations, as shown theoretically by Chakraborty and Weiss [7]. It is therefore important to examine empirically the relationship of LD in the admixed population and allele frequency difference between parental populations. In fact, there have been many studies that have investigated LD patterns in recent admixed populations, such as the AfAs, Mexicans, and Hispanics. In Asia, the only study published so far is on the Uyghurs in Xinjiang, China [35].
In practice, the principle of admixture mapping, proposed by McKeigue [1], is a little different from that of MALD, because it is based on the association of local chromosomal ancestry with the disease rather than on LD between the marker and phenotype, but the information and essence are the same. It is most advantageous to apply this approach to populations that have descended from a recent mix of two ancestral groups that have been geographically isolated for many tens of thousands of years, providing new insights into population history and genotype-phenotype relationships. With the efforts of many scientists in this field, statistical methods, panels of AIMs for admixture typing, and software programs have been rapidly developed; in addition, recent advances in genotyping and sequencing technologies have facilitated genomewide investigation of human genetic variations. Admixture mapping has been applied to a wide range of traits and diseases, for which it is hypothesized that the differences in disease rates across populations are due to population-specific frequency differences of the causal variant(s).
Ancestry Informative Markers
To apply admixture mapping, a set of genetic markers called AIMs, provide information at each locus of the ancestral origin of the allele. An AIM is a polymorphic locus that exhibits substantially different allele frequencies between the ancestral populations, which are often from different geographical regions. For example, Fig. 1 shows an allele frequency distribution of 9,781 AIMs screened from genomewide SNPs from European (EUR) and East Asian (EAS) populations. With a set of AIMs, one can estimate the geographical origins of the ancestors of an individual and ascertain what proportion of the ancestry is derived from each geographical region. The primary utility of estimates of continental ancestry using AIMs is to control for confounding from population stratification in genetic association studies among unrelated individuals from admixed populations. Population admixture has the potential to lead to confounding results from population stratification in genetic association studies, leading to both false positive (type I error) and false negative (type II error) results [36-39]. Now, to facilitate the application of admixture mapping, a number of high-density mapping panels have been constructed, Such panels are already available for disease gene discovery in AfAs [16, 21, 40, 41], Hispanics/Latinos [23, 26, 40], Mexican-Americans (the largest subgroup of Hispanic/Latinos) [28, 41], and Uyghurs [35].
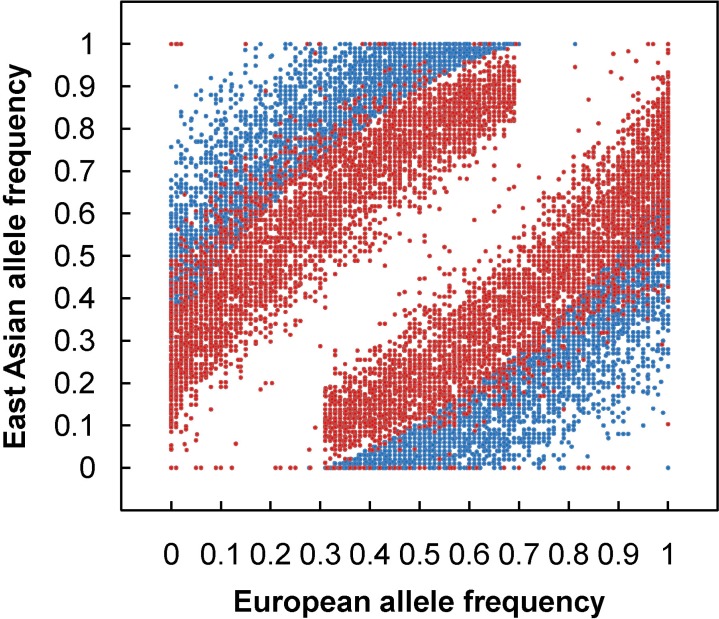
European and East Asian allele frequencies for the 9,781 ancestry informative markers. Blue dots indicate allele frequency of European and East Asian populations. Red dots indicate allele frequency of an admixed population from Xinjiang.
Local Adaptation of Admixed Populations
Identifying targets of positive selection in humans has been a central topic in human evolutionary and population genetics. Traditional studies have been relying on the analysis of individual candidate genes. Since the genomics era, the availability of high-density SNPs has provided essential resources for systematically interrogating the entire genome for detecting signatures of natural selection. As a matter of fact, many genomewide scans for recent or ongoing positive selection have been recently performed in humans, while most of the studies to date have been performed in non-admixed populations. In the situation of genetic admixture, when previously isolated populations meet and mix, the resulting admixed population can benefit from several genetic advantages, including increased genetic variation, the creation of novel genotypes, and the masking of deleterious mutations, and these admixture benefits are thought to play an important role in biological adaptation to local environment. As a result, this has led to the use of admixture estimates to detect the action of natural selection in human populations. Such techniques have been regarded as powerful methods for the detection of selection effects, especially when an appreciable number of generations have elapsed since the original admixture.
Several studies based on genomic data have been conducted in recently admixed populations in the New World [42-44]. Recently, we developed a new approach that can be used to detect natural selection both before and after population admixture, and we applied this method in AfA data. It is particularly meaningful to investigate natural selection in AfAs due to the high mortality their African ancestry has experienced in history. In this study, we examined 491,526 autosomal SNPs genotyped in 5,210 individuals and conducted a genomewide search for selection signals in 1,890 AfAs. Several genomic regions showing excess African or EUR ancestry, which were thought of as the footprints of selection since population admixture, were detected based on a commonly used approach. However, we also developed a new strategy to detect natural selection both pre- and post-admixture by reconstructing an ancestral African population (AAF) from inferred African components of ancestry in AfAs and comparing it with indigenous African populations (IAF). Interestingly, many selection candidate genes identified by the new approach were associated with AfA-specific high-risk diseases, such as prostate cancer and hypertension, suggesting an important role that these disease-related genes might have played in adapting to a new environment. CD36 and HBB, whose mutations confer a degree of protection against malaria, were also located in the highly differentiated regions between AAF and IAF. Further analysis showed that the frequencies of alleles protecting against malaria in AAF were lower than that in IAF, which is consistent with the relaxed selection pressure of malaria in the New World. There is no overlap between the top candidate genes detected by the 2 approaches, indicating the different environmental pressures AfAs experienced pre- and post-population admixture. We suggest that the new approach (see Fig. 2 for a schematic framework of this approach) is reasonably powerful and can also be applied to other admixed populations, such as Latinos and Uyghurs.
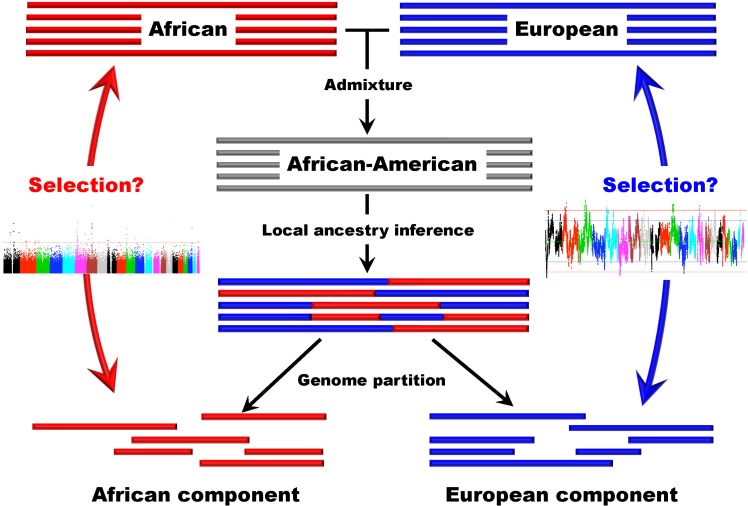
A schematic framework for detecting natural selection in African-American populations based on admixture analysis.
I will not go further on this topic in this review paper, since so far there is no study that has been performed in Asian populations using admixture analysis. However, we believe that the discoveries have greatly enriched our understanding of human origins and history and hold large potential for identifying genes with important biological functions; this, in turn, will elucidate the genetic basis of some human diseases [45, 46]. These studies together provide many new insights into the natural selection process and mechanisms, which will ultimately improve the modern evolution theory.
Population Admixture Dynamics
Human diasporas over the past millennia have resulted in even more frequent intercontinental marriages and population admixtures. Many recently admixed populations, such as AfAs and Mestizos, have received much attention due to their potential advantages in the discovery of disease-associated genes. Particularly, a disease gene mapping strategy, named admixture mapping or MALD, as aforementioned, has been developed [1, 7, 11, 47]. The statistical power of admixture mapping or MALD relies on the fact that population admixture creates extended and elevated LD between loci with different allele frequencies among the parental source populations [7, 10, 48], while the historical population admixture processes determine the LD pattern in an admixed population. Therefore, as shown in several theoretical and simulation studies, population admixture dynamics have a strong effect on the power of admixture mapping [48-51].
In fact, accurate understanding of population admixture dynamics is important not only to admixture mapping but also to other applications, such as elucidating population history [52] and detecting natural selection signatures in admixed populations [49, 53]. However, the fine admixture dynamics of recently admixed populations has not been well established, even though some studies have examined the simulated data [54, 55] or experimental data with sparse markers [48, 51]. In addition, admixture dynamics of relatively ancient admixed populations has rarely been studied. Recently, the availability of genomewide high-density SNPs data has facilitated the study on detailed genetic structures of admixed populations [35, 44, 56-61]. However, most of these studies relied on simplified models that do not take into account the inherent complexity of the admixture processes. Moreover, the haplotype and chromosomal segment patterns shaped by recombination within each individual have been deliberately ignored in most studies due to many inherent challenges [62].
For individuals from admixed populations that have existed for a long time, their chromosomes resemble a mosaic of chromosomal segments of distinct ancestry (CSDA). The CSDA in the admixed population would have been reshaped and rearranged by recombination in each generation, which should provide some information about the population history. In other words, the CSDA will be spliced into smaller pieces as the number of generations since admixture increases, while the chromosomes from recently admixed individuals contain much longer CSDAs. Information regarding the average CSDA length has been used to infer the number of generations since admixture in various studies [57, 63-66]. However, the distribution of CSDA length may contain more valuable information concerning population admixture history and admixture dynamics, which has not yet been explored.
In a recent study [67], we proposed 2 approaches to explore population admixture dynamics and, by analyzing genomewide empirical and simulated data, demonstrated that the approach based on the distribution of CSDA was more powerful than that based on the distribution of individual ancestry proportions. As a result, analysis of 1,890 AfAs showed that a continuous gene flow (CGF) model (Fig. 3), in which AfAs continuously received gene flow from EUR populations over about 14 generations, best explained the admixture dynamics of AfAs among several putative models. Interestingly, we observed that some AfAs had much more EUR ancestry than the simulated samples, indicating substructures of local ancestries in AfAs that could have been caused by individuals from some particular lineages having continuously inter-married with people of EUR ancestry. On the contrary, the admixture dynamics of Mexicans was more likely to be explained by a gradual admixture (GA) model (Fig. 3), in which Mexicans continuously received gene flow from both EUR and Amerindian populations for about 24 generations. The higher proportion of long CSDAs observed in Mexican-Americans relative to Mexican-Mestizos suggested recent gene flow from EUR-Americans to Mexican-Americans. The genetic components of sub-Saharan Africans in Middle Eastern populations, such as Mozabite, Bedouin, and Palestinians, could be explained by one early admixture followed by some recent gene flow from Africans. In summary, this study not only provides new approaches to explore population admixture dynamics but also advances our understanding on historical admixture processes of AfAs, Mexicans, and Middle Eastern populations.
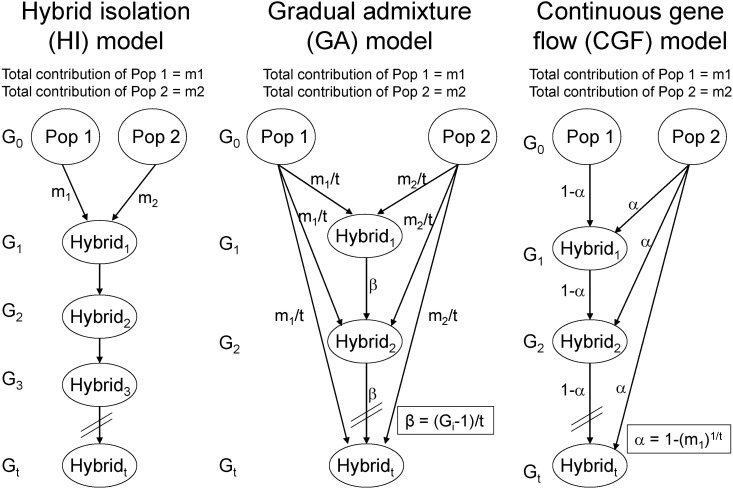
Typical admixture models. HI model and CGF model were adapted from Long [49], GA model was adapted from Ewens and Spielman [50]. In each model, the genetic contributions of Pop1 and Pop2 are m1 and m2, respectively. The admixed population experienced Gi generations, which range from 1 to t generations.
Again, since admixed populations in Asia have not been studied, I will not go further into details. This approach can be also applied in admixed populations in Asia to explore the admixture dynamics of admixed populations in Asia.
Genetic Structure and History of Admixed Populations in Different Geographical Regions
In the following, I will review the studies on population admixture in different geographical regions in Asia-i.e., East Asia, Central Asia, Southeast Asia, and South Asia.
Population Admixture in East Asia
In East Asia, most of the populations that have been studied are thought to be relatively homogeneous. Most people identify themselves with one particular ethnic group, but in fact, we are highly mixed. A report from the HUGO PanAsia SNP Consortium, which was published in Science in 2009 [68], revealed a picture of prevalent gene flow among Asian populations. As a collaborative effort of 93 scientists from 10 countries, this study conducted the first large-scale and genomewide study on the genetic diversity of 73 Asian populations, representing a broad geographic sample of the major ethnic groups and linguistic families in Asia.
Considerable gene flow among Asian populations was observed amongst sub-populations in these clusters, including those groups believed to practice endogamy based on linguistic, cultural, and ethnic information. In fact, most populations studied show evidence of admixture in population structure analyses. For example, the Han Chinese have grown to become the largest ethnic group today, in a demographic expansion that has occurred mostly within historical times. The analysis in this study reveals that the 6 Han Chinese populations show varying degrees of admixture (Fig. 4) between a northern 'Altaic' cluster and a 'Sino-Tibetan/Tai-Kadai' cluster, which is most frequent in the ethnic groups sampled from southern China and northern Thailand. Finally, most of the Indian populations showed evidence of shared ancestry with EUR populations, which is consistent with our understanding of the expansion of Indo-EUR speaking populations (Fig. 4).

Estimated population structure. Each individual is represented by a thin vertical line, which is partitioned by STRUCTURE into K colored segments representing estimated membership fractions in each K cluster. Black lines separate individuals of different populations. Populations are labeled below the figure. All population IDs except the 4 HapMap samples (YRI, CEU, CHB, and JPT) are denoted by 4 characters. The first 2 letters indicate the country where the samples were collected or (in the case of Affymetrix) genotyped according to the following convention: AX, Affymetrix; CN, China; ID, Indonesia; IN, India; JP, Japan; KR, Korea; MY, Malaysia; PI, Philippines; SG, Singapore; TH, Thailand; TW, Taiwan. The last 2 letters are unique IDs for the population. Populations from the same linguistic group or neighboring geographic locations tend to share the same cluster. At K = 14, each language family can be specified by a cluster (color), although Sino-Tibetan-speaking populations tend to cluster with both Altaic- and Tai-Kadai-speaking populations. The figure shown for a given K is based on the highest probability run of 10 STRUCTURE runs at that K.
Population Admixture in Central Asia
Many human populations that settled in Central Asia demonstrate an array of mixed anthropological features of East Eurasians (EEA) and West Eurasians (WEA), indicating a possible scenario of biological admixture between already differentiated EEA and WEA populations. However, their complex biological origin and genomic make-up, as well as their genetic interaction with surrounding populations, are not well understood. Despite Central Asia being a vast territory that has been crucial in human history due to its strategic location [69], populations in this region are not on the list of the 2 large-scale international collaborative efforts, such as the International HapMap Project [70] and the 1000 Genome Project [71], and population genomic studies on Central Asian populations have been largely underrepresented in similar efforts worldwide [68, 72-76].
In an attempt to decipher the genetic structure and population history in Central Asia, we conducted, to our knowledge, the first genomewide studies of the Uyghur residing in Xinjiang, which is geographically located in Central Asia. Uyghur that settled in Xinjiang of China (UIG) is a population presenting a typical admixture of eastern and western anthropometric traits; we dissected its genomic structure at the population level, individual level, and chromosome level using 20,177 SNPs spanning over almost the entire chromosome 21. Our results showed that UIG was formed by two-way admixture, with 60% of ancestry from EUR and 40% of ancestry from EAS. Overall LD in UIG was similar to that in its parental populations, represented by EAS and EUR for common alleles, and UIG manifested elevation of LD only within 500 kb and at a level of 0.1 < r2 < 0.8 when AIMs were used. The size of chromosomal segments that were derived from EASs and EURs was on average 2.4 cM and 4.1 cM, respectively. Both the magnitude of LD and fragmentary ancestral chromosome segments indicated a long period of history of Uyghur. Under the assumption of a hybrid isolation (HI) model, the admixture event of UIG was estimated to have taken place about 126 (107-146) generations, or 2,520 (2,140-2,920) years ago, assuming 20 years per generation. In spite of the long history and short LD of Uyghur compared with recent admixture populations, such as African-Americans, we suggested that MALD is still applicable in Uyghur, except that about 10-fold AIMs are necessary for a whole-genome scan.
Later in the same year, following up on our previous study, we conducted a genomewide analysis of admixture for 2 Uyghur population samples (HGDP-UG and PanAsia-UG) collected from northern and southern Xinjiang of China, respectively. Both HGDP-UG and PanAsia-UG showed substantial admixture of EAS and EUR ancestries, with an empirical estimation of ancestry contribution of 53:47 (EAS:EUR) and 48:52 for HGDP-UG and PanAsia-UG, respectively. The effective admixture time under a model with a single pulse of admixture was estimated to be 110 generations and 129 generations; i.e., admixture events occurred about 2,200 years and 2,580 years ago for HGDP-UG and PanAsia-UG, respectively, assuming an average of 20 years per generation. Despite their earlier history versus other admixture populations, such as AfAs and Latinos, admixture mapping, an economical and powerful approach for localizing disease genes, holds equal promise for Uyghurs because of their mixture of ancestry from different continents as well as their large population size. We screened multiple databases and identified a genomewide SNP panel that can distinguish EAS and EUR ancestry of chromosomal segments in Uyghurs. The panel contains 8,150 AIMs showing large frequency differences between EAS and EUR (FST > 0.25, mean FST = 0.43) but little frequency difference (7,999 AIMs validated) within both EAS and EUR populations (FST < 0.05, mean FST < 0.01). We evaluated the effectiveness of this admixture map for localizing disease genes in 2 Uyghur populations. Our map constitutes the first practical resource for admixture mapping in Uyghurs, and it will enable studies of diseases showing different genetic risks in European and EAS populations.
Population Admixture in Southeast Asia
Southeast Asia, together with the Island Pacific region, is a cultural melting pot of migrating Neolithic farmers and indigenous Mesolithic hunter-gatherer communities. On the basis of increased cultural, linguistic, and genetic diversity, the origins of Southeast Asian populations are thought to be more complex than those to their north. Two major prehistoric movements of people had great influence on the linguistic, cultural, and genetic diversity of the region. The first colonization of modern humans in the region was around 45,000 years before the present [77], which could have brought the ancestors of modern Papuans and Australians into the region [78]. Notably, archaeological evidence has confirmed human habitation in Eastern Indonesia as far back as 32,000 years ago [79]. The second major human migration event, which is often termed the Austronesian expansion, was relatively recent, coinciding with the first agricultural settlements in Island Southeast Asia (ISEA) [80]; it is often putatively linked to demic dispersal from mainland China during the Mid-Holocene [81], and based on linguistic studies, the Austronesian expansion is proposed to have originated in Taiwan around 5,000-6,000 years ago and spread to Southeast Asia, Near and Remote Oceania, and Madagascar [82, 83]. However, our knowledge about the historical origin and spread of Austronesian-speaking peoples has been overwhelmingly from linguistic, archeological, and anthropological studies, while contributions from genetic studies are limited, and especially, genetic dating of the expansion time of Austronesians is almost absent [84].
Undoubtedly, the Austronesian expansion has had a major cultural influence on Asia-Pacific pre-history. The biological contribution of Austronesian-speaking peoples to the pre-existing local populations in ISEA was first noted by Wallace in 1869 [85]. As Wallace observed, people in the region between mainland Asia and New Guinea in the west are similar to their neighbors in mainland Southeast Asia, while the eastern groups near New Guinea are similar to Melanesians, leaving intervening populations intermediate in appearance [85]. This admixture pattern was revealed by mtDNA and non-recombining region of the Y chromosome (NRY) studies [86, 87] as well as by a recent study [81] based on multiple autosomal and X-chromosomal SNPs.
The genetic admixture with local populations during the Austronesian expansion could provide a unique opportunity to shed light on the migration history of Austronesian-speaking people. However, previous studies based on haploid genomes could not study admixture at the individual level. Studies of multiple loci of the nuclear genome are more powerful [88] in studying admixture at the individual level, but the sparse low-density loci examined in previous genomewide studies do not allow estimation of the admixture time, which relies on recombination information extracted from high-density genomewide data.
We analyzed dense genomewide SNP data from 2 studies [68, 89]. The first consists of about 50,000 SNPs analyzed in 288 individuals from 13 Austronesian-speaking populations and 2 Papuan-speaking populations across Indonesia and Papua New Guinea, while the second consists of about 680,000 SNPs analyzed in 36 individuals from 7 populations from Indonesia and 25 individuals from New Guinea. Apart from a general description of population structure and its relationship with geography, language, and demographic history, we focus on estimating the amount and time of admixture involving Asian and Papuan ancestry across E. Indonesia to test the various scenarios that might explain the admixture history. Because genetic recombination breaks down parental genomes into segments of different sizes, the genome of a descendant of an admixture event is composed of different combinations of these ancestral segments, or 'blocks' [90]. Admixture time can be estimated from the information based on distribution of ancestral segments and the recombination breakpoints in an admixed genome [34, 57, 63, 66, 90]. In this study, we assume that a cline of admixture times that decreases from west to east across E. Indonesia would support a scenario of incoming Asians admixing with indigenous Papuan groups, while a cline in the opposite direction would indicate incoming Papuans admixing with resident Asians. Moreover, the actual admixture times would indicate when the migration occurred. Our approach is thus to estimate population admixture time by taking advantage of available genomewide data of both E. Indonesian populations showing admixture and their ancestry reference populations.
In summary, the admixture time analysis of 2 different datasets provides compelling evidence that people of Asian ancestry began moving through E. Indonesia about 4,000 years ago, from west to east, and admixed with resident groups of Papuan ancestry. Furthermore, this scenario is in excellent agreement with linguistic and archeological evidence for a pre-Austronesian presence of Papuans in E. Indonesia [91, 92] and for an eastward spread of Austronesian-speaking farmers across E. Indonesia [82, 83]. Our analyses thus refute suggestions that the Asian ancestry observed in Indonesia largely predates the Austronesian expansion [93, 94]. Instead, our analyses of genomewide data indicate that there was a strong and significant genetic impact associated with the Austronesian expansion in Indonesia, just as similar analyses have pointed to a strong and significant genetic impact associated with the Austronesian expansion through Near and Remote Oceania [87, 95, 96]. Given that admixture among human populations (and between modern and archaic humans) is increasingly being recognized as a significant aspect of modern human biology [97], estimates of the time of admixture should provide important new insights into the history of our species.
Population Admixture in South Asia
All the published results in this area so far have been focused on populations in India. There were recently 2 studies on the Siddis, which are a group of people showing evident genetic admixture in India. The Siddis (Afro-Indians) are a tribal population whose members live in coastal Karnataka, Gujarat, and some parts of Andhra Pradesh. Historical records indicate that the Portuguese brought the Siddis to India from Africa about 300-500 years ago; members of this population are believed to be descendants of the Bantu-speaking population of Africa. However, there is little information about their more precise ancestral origins. One Indian group, led by Dr. Mukerji, studied this population [98] based on genomewide SNP data generated using Affymetrix 50K chips. The authors carried out this study by using a set of 18,534 autosomal markers common between Indian, CEPH-HGDP, and HapMap populations. Principal components analysis clearly revealed that the African-Indian population derived its ancestry from Bantu-speaking west African as well as Indo-European-speaking north and northwest Indian population(s). STRUCTURE and ADMIXTURE analyses show that overall, the OG-W-IPs derived 58.7% of their genomic ancestry from their African past and have very little inter-individual ancestry variation (8.4%). The extent of LD also reveals that the admixture event has been recent. Functional annotation of genes encompassing the AIMs that are closer in allele frequency to the Indian ancestral population revealed significant enrichment of biological processes, such as ion channel activity, and cadherins. They briefly examined the implications of determining the genetic diversity of this population, which could provide opportunities for studies involving admixture mapping.
The second group, led by Dr. Thangaraj, performed a genomewide survey to understand the population history of the Siddis [99]. Using hundreds of thousands of autosomal markers, they showed that the Siddis inherited ancestry from Africans, Indians, and possibly Europeans (Portuguese). Additionally, analyses of the uniparental (Y-chromosomal and mitochondrial DNA) markers indicate that the Siddis trace their ancestry to Bantu speakers from sub-Saharan Africa. They estimated that the admixture between the African ancestors of the Siddis and neighboring South Asian groups probably occurred in the past 8 generations (-200 years ago), consistent with historical records.
Perspective
Recent advances in genotyping and sequencing technologies have facilitated genomewide investigation of human genetic variations and provided new insights into population structure and admixture history. Admixed populations are attracting more and more attention from both evolutionary and medical studies as well as from the other fields. Without understanding the genetic structure and history of admixed populations well, our knowledge about human genetics would not be complete. Unfortunately, studies on admixed populations in Asia are so far very limited, although gene flow among Asian populations is prevalent [68]. The studies published and mentioned in this review have been focused on investigating the genetic structure and genetic history of a limited number of well-known admixed populations in Asia. Further efforts should be made to reveal local adaptation signatures and also apply admixture mapping in those well-known admixed populations; in the future, more powerful methods are expected to be developed and applied to many more populations with longer histories and more complex admixture scenarios.
Acknowledgments
This work was supported by the National Science Foundation of China (NSFC) grants 31171218 and 30971577, by the Shanghai Rising-Star Program 11QA-1407600, and by the Science Foundation of the Chinese Academy of Sciences (CAS) (KSCX2-EW-Q-1-11; KSCX2-EW-R-01-05; KSCX2-EW-J-15-05). This research was supported in part by the Ministry of Science and Technology (MoST) International Cooperation Base of China. Shuhua Xu is Max-Planck Independent Research Group Leader and member of CAS Youth Innovation Promotion Association. Shuhua Xu also gratefully acknowledges the support of the National Program for Top-notch Young Innovative Talents and the support of the K.C. Wong Education Foundation, Hong Kong.