Confidence intervals for the COVID-19 neutralizing antibody retention rate in the Korean population
Article information

Abstract
The coronavirus disease 2019 (COVID-19), caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), has become a global pandemic. No specific therapeutic agents or vaccines for COVID-19 are available, though several antiviral drugs, are under investigation as treatment agents for COVID-19. The use of convalescent plasma transfusion that contain neutralizing antibodies for COVID-19 has become the major focus. This requires mass screening of populations for these antibodies. While several countries started reporting population based antibody rate, its simple point estimate may be misinterpreted without proper estimation of standard error and confidence intervals. In this paper, we review the importance of antibody studies and present the 95% confidence intervals COVID-19 antibody rate for the Korean population using two recently performed antibody tests in Korea. Due to the sparsity of data, the estimation of confidence interval is a big challenge. Thus, we consider several confidence intervals using Asymptotic, Exact and Bayesian estimation methods. In this article, we found that the Wald method gives the narrowest interval among all Asymptotic methods whereas mid p-value gives the narrowest among all Exact methods and Jeffrey’s method gives the narrowest from Bayesian method. The most conservative 95% confidence interval estimation shows that as of 00:00 on September 15, 2020, at least 32,602 people were infected but not confirmed in Korea.
Introduction
Several unexplained pneumonia cases have been successively discovered in Wuhan, Hubei province of China, in early December 2019, which have been confirmed to be severe acute respiratory syndrome caused by a novel coronavirus 2 (severe acute respiratory syndrome coronavirus 2, SARS-CoV-2) and has spread rapidly across the globe [1]. The spread of coronavirus disease 2019 (COVID-19) became a global threat and the World Health Organization (WHO) declared COVID-19 a global pandemic on March 11, 2020 [2]. As of September 18, 2020, there were a total of 30,358,087 confirmed cases and 950,635 deaths from COVID-19 worldwide [3].
No specific therapeutic agents or vaccines for COVID-19 are available yet [4]. Accurate and fast diagnosis of the SARS-CoV-2 is one of the most important methods used to isolate patients with COVID-19 and stop the spread of the epidemic, as well as save people’s lives [5] The current recommendations for laboratory diagnosis of COVID-19 from the Center for Disease Control (CDC) are that clinicians coordinate this testing with local public health authorities and/or the CDC. Viral nucleic acid detection using real-time reverse-transcription polymerase chain reaction assay, like that developed for the diagnosis of SARS-CoV, was developed and used for rapid detection of SARS-CoV-2 and remains the gold standard for diagnosis of COVID-19 [6].
Although several antiviral drugs, such as the nucleotide analogue remdesivir and favipiravir, are under investigation as treatment agents for COVID-19, the antiviral efficacy of these drugs is not yet known [4,7]. In addition to vaccine development and approaches that directly target the virus or block viral entry, treatments that address the immunopathology of the infection have become a major focus. The use of convalescent plasma was recommended as an empirical treatment during outbreaks of Ebola virus in 2014 and the treatment of Middle East respiratory syndrome coronavirus in 2015 [8,9]. This approach was effective with other viral infections such as SARS-CoV, H5N1 avian influenza, and H1N1 influenza [10], through a single convalescent plasma transfusion [11-13]. Treatment of severe infections of patients of influenza A(H1N1) 2009 pandemic with convalescent plasma was associated with reduced respiratory tract viral load, serum cytokine response, and mortality [10]. Also, the study involving 80 patients with SARS showed that administration of convalescent plasma was associated with a higher rate of hospital for patients who received the convalescent plasma than with patients who did not receive the plasma [10,14].
In addition, high-throughput platforms, such as the large-scale single-cell RNA sequencing of B cells (enriched for B cells that produce antibodies directed at the SARS-CoV-2 spike glycoprotein) from patients who are convalescent, have allowed the identification of SARS-CoV-2-specific neutralizing antibodies [6]. Neutralizing antibodies is said to play an important role in virus clearance and have been considered as a key immune product for protection or treatment against viral diseases. Convalescent plasma containing identified SARS-CoV-2–specific neutralizing antibodies has already been used to treat a small number of patients with severe disease, and preliminary results show clinical improvement in 5 of 5 critically ill patients with COVID-19 who had developed acute respiratory distress syndrome [6,10]. All these findings raise the hypothesis that use of convalescent plasma transfusion is beneficial in patients infected with SARS-CoV-2 and solidifies the importance of large-scale antibody testing for COVID-19 [15].
A COVID-19 antibody test, also known as a serology test, is a blood test that can detect if a person has antibodies to SARS-CoV-2. An antibody test checks for antibodies (proteins made by the immune system to fight infections like viruses and may help to ward off future occurrences by those same infections) in the blood. Human bodies make antibodies when we catch an infection to help fight the infection [16,17]. If coronavirus antibody is present in the blood, it's likely he/she had the virus before. The value of antibody tests is currently limited to (1) answering the question of whether someone has had the virus before, (2) providing data and a greater understanding on the spread of the virus [18]. Also, given the unknown scale of asymptomatic infections (infected patients without symptoms), there is a pressing need for serological diagnosis to represent the real number of COVID-19 infected patients which determines the true extent of infection in a given country [19]. Serological tests are known to be in use in Europe, United States, Japan and other developed countries to figure out how many people are infected with the potentially deadly virus [20]. For example, results from Spain’s final stage of a nationwide antibody study shows that Spain’s antibody retention rate is believed to be 5% [21] while London, Stockholm, and Tokyo have a retention rate of 17%, 7.3%, and 0.1%, respectively [22]. While viral RNA-based testing for acute infection is the current standard, surveying antibody protection is a necessary for discovering the real extend of coronavirus infections in a population and for return to social normality [19,20].
Other importance for COVID-19 antibody testing include; to identify donors with high-neutralizing titers for convalescent plasma for therapy and define correlates of protection from SARS-CoV-2 [19].
Methods
Materials
Recently, Korea Centers for Disease Control and Prevention (KCDC) announced the discovery of neutralizing antibodies for COVID-19 from two investigative screening surveys carried in South Korea. The first antibody screening results reported; 0 neutralizing antibodies were discovered out of 1,555 serum samples collected for antibody titer from subjects who participated in the Korea National Health and Nutrition Examination Survey (KNHANES) from April 21 to June 16 from 14 cities and provinces in South Korea excluding Daegu (which was the city for the major COVID-19 outbreak in Korea in early March), Daejeon and Sejong (0/1,555) and neutralizing antibodies was identified in only one sample out of 1,500 serum samples collected from May 25 to 28 from patients visiting a medical institution in southwestern Seoul (1/1,500) [22]. The second antibody results reported that neutralizing antibodies were confirmed in only one sample out of 1,400 serum samples collected for antibody titer from subjects who participated in KNHANES from June 10 to July 13 in 13 cities and provinces including Daegu, Daejeon, and Sejong (1/1,400).
The above reported dataset only captures a sample proportion but does not provide its confidence interval. This kind of result reporting can mislead the public especially to people without any statistical knowledge. Based on these sample datasets, we will use inferential statistics for deciding for whole population in Korea about COVID-19 antibody screening studies. Because our sample data is sparse, point estimation (i.e., sample proportion) gives some misleading interpretations, for example; 0/1,555 sample proportion shows that there are no neutralizing antibodies present in the Korean population, and so it is good to report point estimation along with proper interval estimation. In paper, we present intervals (95% confidence intervals) for the above reported Korean COVID-19 neutralizing screening antibody results using known Asymptotic, Exact, and Bayesian estimation methods.
Methods
As one method doesn’t give the optimal confidence interval range, we present confidence intervals calculated using different methods that can apply the point estimate results above. There are many methods available for calculation of confidence intervals for various parameters and those methods are mainly divided into three different type of estimation techniques, such as asymptotic estimation, exact estimation, and Bayesian estimation. In this section, we have reviewed the likelihood function for binomial proportion as well as the methods for confidence interval.
Likelihood function for binomial parameter
Let we conduct n iid Bernoulli experiments with probability of success π and find y successes. Then the likelihood function can be defined as
and the log-likelihood function is
Maximum likelihood estimator of π is
Asymptotic estimation (large sample approximation)
Confidence intervals can be obtained by inverting the association test [23]. For instance, a 95% confidence interval for the population proportion π is the set of π0 for which test of H0:π=π0 has p-value exceeding 0.05 [23]. Wald, Score, and Likelihood-ratio are the three main asymptotic methods for estimating confidence intervals as described below.
Wald confidence interval
The 100(1-α)% wald confidence interval is
where zα/2 is the z-score form the standard normal distribution with right tailed probability α/2.
Likelihood-ratio-based confidence interval (LR)
The 100(1-α)% likelihood-ratio-based confidence interval is
where L(π) is the maximized value of likelihood function under H0:π = π0 and L(
Score-based confidence interval
The 100(1-α)% score-based confidence interval is
where u(π) is the score function derived from the log-likelihood function.
Exact estimation
For both small and large to moderate samples, population proportion inference can occur both near 0 or 1, and both are not good. In such cases, asymptotic methods may have inadequate performance and provide quite different confidence intervals [23]. Therefore, we use alternative estimation techniques, such as exact sample inference and Bayesian sample inference. For exact estimation, we use the Clopper-Pearson and the mid p-value methods. Clopper-Pearson interval is based on inverting the tailed binomial tests for forming confidence intervals [24]. For a binomial data with parameter π (success), the endpoints are the solution of
and the lower bound is 0 when y=0 and the upper bound is 1 when y=n. Unfortunately, with the discrete probability distributions, it is usually not possible for a p-value to achieve the desired significance level exactly [24], so we use the mid p-value
Mid p-value:
For small samples of discrete data, it seems sensible to use adjustment of exact methods based on the mid p-value [25]. For a test statistic T with observed value t0 and one-sided alternative hypothesis, the mid p-value is obtained by
where probability, p calculated from the null distribution. The two-sided mid p-value is
Bayesian estimation
Aforementioned (asymptotic estimation and exact estimation) approaches are known as the frequentist approach and requires a random process that produces the observed data [26]. That is, the parameter value is assumed to be unknown, but a fixed quantity and obtained from the observed data. Recent years have been seen with increasing popularity of this Bayesian approach, which considers the parameter is a random quantity and whose value can be described by a probability distribution, known as prior distribution and fixed data. Bayesian approach combines the prior with observed data to create a posterior for the parameters using the Bayes equation;
where π is the unknown parameter, y is the observed data and the denominator p(y) is the marginal probability function of the data, which is a constant with respect to π. The Bayes equation then simplifies to
The above equation gives the posterior probability of π, p(π│y), as a function of likelihood p(y│π) and prior p(π). Therefore, we need to choose the prior information, which is the most difficult aspect in Bayesian approach. If there is lack of prior information one can use uniform prior, which can be got from literature if a pilot study has been conducted, which turns out to be a non-informative prior. The most popular non-informative choice of prior is Jeffrey’s prior, defined as
In binomial setting, the Jeffrey’s prior for binomial data is π~Beta (
Because the parameter π is a random variable in Bayesian techniques, it allows for making ideal statements concerning the probability of the parameter and confidence intervals. This confidence interval contains most of the posterior distribution and is known as the posterior interval or credible interval.
Results
Table 1 presents the 95% confidence intervals for the first antibody results using only the KNHANES samples and for the total population in South Korea. The first two columns show the methods and the next two columns the 95% confidence interval for antibody retention rate in the samples. The final two columns represent the estimated 95% confidence interval of antibody carriers in Korean population by multiplying the total number of Korean population (51,780,579 people) with the antibody ratio (the proportion of samples with neutralizing antibodies provided as confidence intervals) from September 19, 2020. Note that this estimation was derived from a simple random sampling assumption, while the antibody sample does not represent the total Korean population.

95% Confidence intervals (CIs) for the first antibody results using the KNHANES samples only and for the total population in South Korea
From Table 1, the Wald method fails to provide confidence interval. LR gives the minimum upper bound which is 63,690 and it also provides narrower confidence intervals among all types of confidence intervals’ methods. Score, Exact and Uniform methods gives similar interval.
Table 2 presents the 95% confidence intervals for the first antibody results using only the Seoul samples and for the total population in South Korea. Table 3 presents the 95% confidence intervals for the first antibody results using both Seoul and KNHANES samples (1,555 + 1,500) and the total population in South Korea. Table 4 presents the 95% confidence intervals for the second antibody results using only the KNHANES samples (1,440) and for the total population in South Korea. Table 5 presents the 95% confidence intervals for the sum of the first and second antibody results using the KNHANES + Seoul + KNHANES samples and for the total population in South Korea. The first two columns show the methods and the next two columns the 95% confidence interval antibody ratio in the total samples (1,555 + 1,500 + 1,440).
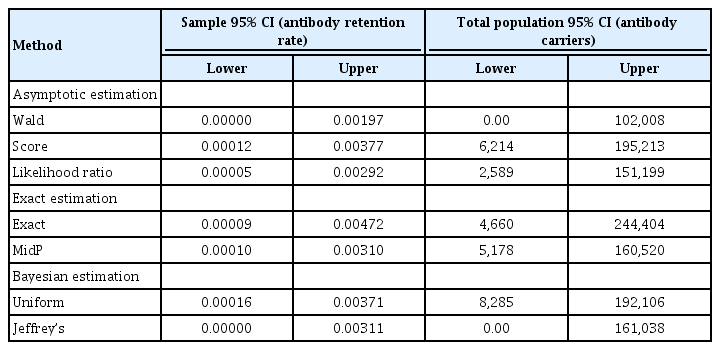
95% Confidence intervals (CIs) for the first antibody results using only samples from Seoul area and for the total population in South Korea

95% Confidence intervals (CIs) for the first antibody results using both KNHANES + Seoul sample size only and for the total population in South Korea

95% Confidence intervals (CIs) for the second antibody results using only KNHANES sample portion and for the total population in South Korea

95% Confidence interval (CI) using the sum of both the first and second antibody results sample size and for the total population
For all cases, the Wald method gives the narrowest interval and smallest upper bound values, except in Table 1 (102,008, 50,227, 104,079, and 54,887, respectively) among all the asymptotic estimation methods. mid p-value method among exact estimation and Jeffrey’s method among Bayesian estimation, all give the smallest interval. Jeffrey’s and mid p-value methods have similar intervals while Score and Uniform methods have similar interval results. Bayesian Jeffrey’s prior gives better interval than Uniform Prior.
From Tables 1–5, confidence intervals are quite different depending on the method used. We think this inconsistency might be due to sparsity of data and small sample sizes. It is well known that sparsity causes the parameter estimates to fall near the boundary of the parameter space (for example, in proportion parameter value near to 0 or 1). As a result, the asymptotic methods such as the Wald method suffered from the convergence problem. In this sparse situation, either exact methods or Bayesian methods provide more reasonable confidence intervals. With modern computational power, it is not difficult to use exact inference for confidence interval directly from the binomial distribution without using large sample approximation to normality [23]. Due to discreteness, two exact methods provide different result. In Bayesian methods, Jeffrey’s prior provided better results than the uniform prior because it uses prior information for the scales of measurement, while the uniform prior does not use any prior information at all. Also, note that when the sample size was largest (Table 5), all methods provided more similar confidence intervals. In other words, as the sample size increases, all methods are expected to provide quite consistent confidence intervals.
In summary, as the sample size increases, the confidence interval become narrower. That is, as the sample size increases, more accurate estimation of antibody ratio is possible. In the confidence interval, the lower bound can be replaced by the number of confirmed patients through an actual test. Among the upper bound, the smallest value provides a conservative interpretation while the largest value does a more aggressive interpretation. Subtracting today's cumulative number of confirmed cases from the smallest upper limit can be interpreted as the minimum number of cases that were infected but not confirmed. As of 00:00 on September 15, 2020, at least 32,602 (= 54,887–22,285) people were infected but not confirmed. This should be interpreted as having a high probability of cumulative infection.
Discussion
Statistical inference is a kind of process that helps us in making decisions about unknown population based on information contained in a sample taken from the population. There are two types of statistical inference: point estimation and hypothesis testing. The most important aspect of statistical inference is estimation of the unknown parameter, which is a procedure for finding the value of the unknown parameter by using the sample observations. For example, the sample means are used to estimate the population mean, sample proportion are used to estimate the population proportions, etc. An estimate of population parameter can be expressed in two ways: point estimate and interval estimate. A point estimate is a single number that is used to estimate an unknown population parameter. It is not much useful unless some information regarding possible error of estimate is associated with the estimate. For example, the sample proportion
Unfortunately, our study has several limitations. The current sample size for Korean studies is too small for accurate estimation of antibody test of Korean population. For estimation of antibody carriers in Korean population, we simply assumed that our antibody samples were derived from a simple random sampling assumption, because any detailed information of the samples is not available. Furthermore, the antibody samples may not represent the total Korean population well. To make more accurate estimation of antibody carriers in the Korean population, a much large sample size is required to represent the Korean population well. Then, with a further detailed demographic information of subjects and sampling information, more accurate sampling design-based inference can estimate the total number of antibody carriers in Korean population along with its 95% confidence intervals. In addition, there is no detailed information available for antibody test kits. Thus, in our estimations, it is expected that the kits should have high specificity, to accurately diagnose the subject without the COVID-19 antibody as negative, rather than high sensitivity to diagnose the subjects with the antibody as positive. No sensitivity and specificity information was considered in our analysis.
Notes
Authors’ Contribution
Conceptualization: TP. Data curation: MK. Formal analysis: MK. Funding acquisition: TP. Methodology: TP. Writing - original draft: MK. Writing - review & editing: AC, MK.
Conflicts of Interest
No potential conflict of interest relevant to this article was reported.
Acknowledgements
The authors thank Dr. Asaph Young Chun, Ph.D., Director-General, Statistics Research Institute Statistics, Korea for his extremely helpful comments.