Availability: The code for our web service is publicly available (https://github.com/OntoGene/blah5).
Introduction
Dependency parsing might be used as a component for tackling many text mining problems. It is often used as a feature to train machine learning algorithms or used for rule-based approaches for relation extraction [1,2]; and can be used to train better word embeddings [3]. However, as continued research and community efforts in the form of the CoNLL shared tasks, for example, show, dependency parsing in general is still not a problem solved completely [4]. Making a fast, reliable dependency parser readily available for the wider research community for further processing to build upon will help spur efforts in event and relation extraction.
As previous research has shown, providing named entity information to the dependency parser can improve the accuracy of the parses [5,6]. The reasoning is that dedicated named entity recognition (NER) tools perform much better in their specific domain, and by extracting named entities with higher accuracy will facilitate appropriate parsing tools that are not trained on biomedical data.
spaCy is a open-source natural language processing (NLP) library written in Python that performs tokenization, Part-of-Speech (PoS) tagging and dependency parsing. It is the fastest NLP parser available, and offers state-of-the-art accuracy [2,7].
Services such as PubDictionaries and OGER perform dictionary-based entity look up [8]. Other state-of-the-art taggers are the Jensen tagger [9] and TaggerOne [10].
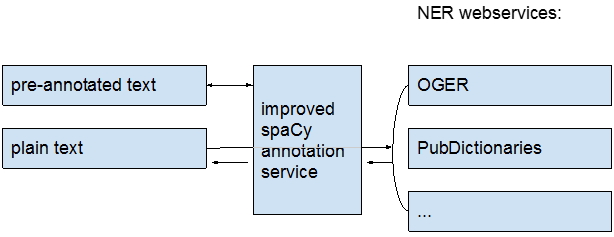
In this work, we present our contribution to BLAH5. We proposed to build a public web service that can be used by researchers and other services, such as PubAnnotation, to obtain improved dependency annotations, based upon integration with a NER service (Fig. 1). We report on its efficacy here.
Related Work
The most recent extensive evaluation of existing dependency parsers has been performed by Choi et al. [11]. They evaluate 10 different off-the-shelf parsers for accuracy and speed; reporting labeled attachment scores (LAS) of 85% to 90%. While spaCy does not perform the most accurate in their evaluation, it performs fastest maintaining comparable accuracy. Similar scores are reported in the 2015 SemEval task [12].
Pletscher-Frankild and Jensen [9] note that in text mining literature, tools are often evaluated for accuracy only, omitting practical considerations such as speed and robustness.
Since the publication of the previously mentioned evaluation of dependency parsers [11], new machine learning-based parsers have been published, surpassing existing approaches according to the respective authors’ own evaluation [13,14]. Amongs them, spaCy was updated to employ a neural network to improve performance [7]. As Yang et al. [15] show, however, domain adaptation remains an issue.
Methods
Our web service is implemented using Flask (http://flask.pocoo.org/), a Python library that facilitates the creating of web interfaces, and the aforementioned spaCy (https://spacy.io). spaCy’s structure is modular, and processing text happens by calling the respective modules. For our approach, we added a further processing step between “tokenization” and “dependency parsing,” during which we will recompute token segmentation taking into account named entities provided. Then we pass the adjusted token offsets to the dependency parsing module.
Input format
Input is provided either as plain text or as a JSON string. The latter may either contain just a text field, or additionally annotations in PubAnnotation's JSON format (http://www.pubannotation.org/docs/annotation-format/) (Fig. 2).
The input is then internally converted into a spaCy object. From there, spaCy is used to perform tokenization, PoS tagging and dependency parsing, taking into account existing annotations if available.
This is done by tokenizing the text provided, and iterating through the given annotations to form a new sequence of tokens. This new sequence keeps the NER annotations as individual tokens and does not break them down further. In case of conflicting and overlapping annotations, we use the leftmost longest match.
Using this new token sequence, a new spaCy representation object is created on which dependency parsing is performed.
If no annotations are provided manually, our web service will automatically call another service to automatically obtain named entity annotations. While this could be any service, it is currently set to using OGER.
Output format
The resulting object is then converted back into JSON, and token offsets are computed. The output format is PubAnnotation JSON, and can directly be uploaded to PubAnnotation. This also allows to make use of PubAnnotation's annotation visualizer, TextAE, as seen in Fig. 3.
Usage
The code for our web service is publicly available (https://github.com/OntoGene/blah5), and installation is straight-forward. For demonstration purposes, we are running an instance of the web service.
Improved dependency annotations can be obtained using curl or wget in the fashion shown in Fig. 4.
Results
We evaluated our service in two regards: speed and accuracy.
Speed
In order to evaluate speed of our web service, we created a set of 10,000 randomly selected PubMed abstracts, (1) which we sent to the web service directly to obtain “default” dependency parses, and (2) which we first tagged for named entities using OGER, and then sent to the web service to obtain “improved” parses. Table 1 lists the time it took our tool to complete the dependency parsing step for both cases.
We attribute this decrease in processing time to the diminished complexity of computing the parses.
In a practical setting, however, our web service needs to recompute token offsets in order to correctly integrate NERs in the token stream.
While spaCy in the “default” case does this in a internally optimized fashion, our service currently is not optimized to the same degree, which in practice results in overall lower processing times. The integration of NERs still produces an advantage, as the generated parses avoid some errors that otherwise would have been generated (see below). In practice, when using the web service over the network, total processing time will be around 0.3 s per abstract.
Accuracy
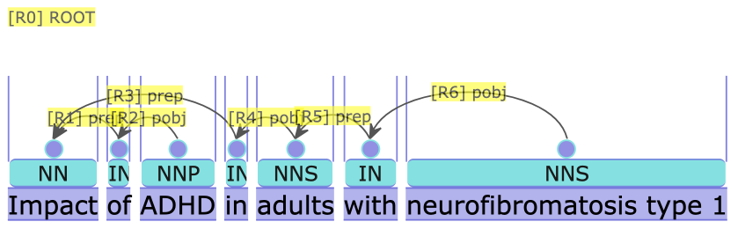
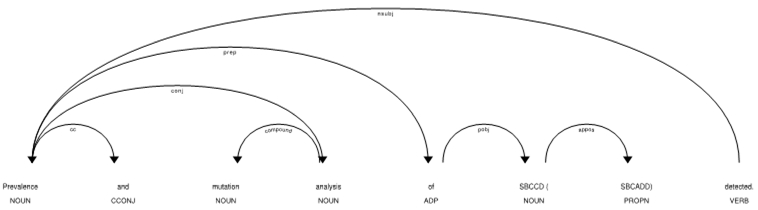
We expect our service to perform well in situations where multi-word named entities cause problems for the parser. Below we demonstrate two examples in which our service performs well in such situations.
Discussion
The examples shown above point to the efficacy of our web service. However, a more thorough evaluation, while useful, is difficult. This is mainly due to the fact that manual creation of parsing annotations is prohibitively expensive, and the fact that existing annotated corpora are annotated in various incompatible formats. For example, depending on the annotation schema, conjunctions can be represented in various ways, or relationships may be either undirected or have opposite directionality. Even though there are efforts to homogenize annotation schemes, such as Universal Dependencies [16], they are not yet widely adopted. This makes automatic comparison of results very difficult. However, since dependency parsing is not usually a goal in itself, but a component used for downstream tasks, an extrinsic evaluation could be carried out on such a downstream task such as relation extraction.