Introduction
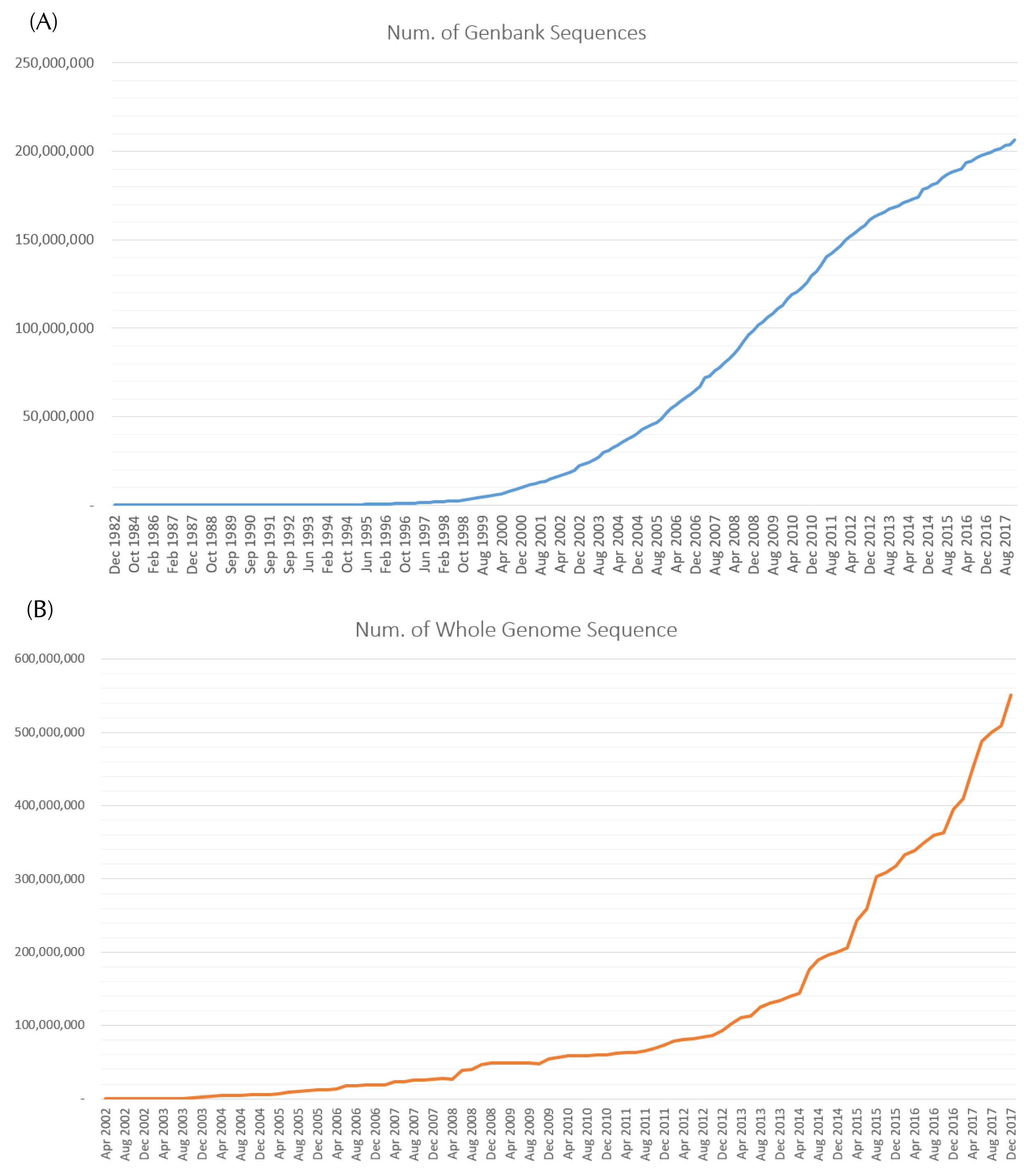
Presently, there are 3,279 virus reference genomes registered in NCBI. More than 1.8 million sequences are included in GenBank (https://www.ncbi.nlm.nih.gov/genbank/) [1]. The number of whole-genome sequences in GenBank is rapidly increasing, as shown in Fig. 1. Currently, only about 1,800 genome sequences have been assigned to species in International Committee on Taxonomy of Viruses (ICTV); the remaining 1,400 sequences have not been classified as species. Although ICTV is responsible for viral classification, it does not have the capacity to immediately formulate the naming conventions and taxonomy for the large number of viral sequences that is submitted to the organization.
However, with the advent of next-generation sequencing and the enhancement of NCBI GenBank data, the classical ICTV method of viral classification based on phenotypic parameters has been converting to a classification based on genotypic classification due to improvements in the speed and accuracy associated with virus taxonomy. Recently, a metagenomic method based on genotype was proposed as an approach to aid virus taxonomy [2]. However, this creates a requirement for an appropriate data handling and analysis pipeline to cope with such needs.
Since the development of web servers in 1993, bioinformatics data have been provided through browser-based systems. Many analysis tools, such as MSA, BLAST, and Genome Browser, have been developed for end users. In the case of ICTV taxonomy and naming, the initial ICTVdB was developed with flat data (DELTA: DEscription Language for TAxonomy), which was not connected to other databases. ICTVdB did not contain any sequence information but was used for phylogenetic analysis [3]. Presently, the 10th ICTV virus taxonomy has been published and is available on the ICTV website (http://ictv.global/report/). However, there is no easy approach to NCBI GenBank data based on ICTV taxonomy, strain, or isolation information for selected viral species, because ICTV taxonomy has only been providing up to the species level. Also, web-based ICTV taxonomy does not provide direct PubMed access, which facilitates academic searches. As a result, our virus taxonomy website reinforces this problem and extends the related tables in the ICTV database.
Methods
ICTV taxonomy and virus history
The gene sequences submitted to NCBI are recorded in GenBank format with a unique key that is generated by the combination of the accession number and version number. The accession number consists of 1 letter and 5 numerals or 2 letters and 6 numerals for nucleotides and 3 letters and 5 numerals for proteins. The GenBank format is structurally divided into meta information, feature information, and sequence information. In this system, due to the types of viral targets, only “gbvrl” data among NCBI GenBank data are collected and used (ftp://ftp.ncbi.nlm.nih.gov/genbank). Currently, it is available from “gbvrl1.seq.gz” to “gbvrl51. seq.gz” (2017/12/20). However, GenBank data are highly redundant due to frequently overlapping submissions. This means that computing or parsing after collecting or manipulating GenBank data is an extremely inefficient process. Therefore, NCBI has provided RefSeq data to minimize redundancy, and there are presently 9,557 complete viral genomic RefSeq sequences. Meanwhile, in International Classification of Viruses (ICNV; the name before being revised to ICTV), the first virus taxonomy of 1,971 included 19 genera and 2 families (Papovaviridae and Picornaviridae), while 24 groups were unassigned until the appropriate classification levels were determined [4]. In the current 10th virus taxonomy on the ICTV website, based on the final version (“ICTVMasterSpeciesList2016v1.3”), there are 4,404 species, whereas there are 9,556 complete genome sequences of viral species in GenBank RefSeq (Table 1).
The goal in our web-based system is to extend the basic information in the ICTV taxonomy database in order to include strain and isolate group and to provide raw data of genomic sequences, as well as history and PubMed information for user-chosen viruses. As a prerequisite, the 10th ICTV taxonomy, which is the most recent, must be parsed. However, ICTV does not provide taxonomy history through OpenAPI. Thus, we collected the data on the taxonomy history and the linked node information via web scraping.
Virus taxonomy database
We collected the ICTV taxonomy from the “ICTV Master Species List,” which was officially announced in ICTV in 2016 (Table 2); the taxonomy history was obtained by web scraping. Furthermore, in order to extend the resource including strain and isolation information and to connect to the viral GenBank information, we downloaded “gbvrl1.seq.gz”~“gbvrl51.seq.gz” (the GenBank virus file) using an FTP protocol and classified the data according to ICTV taxonomy criteria. Currently, the classification table, which is designed in the current ICTV database, includes classification name, classification level, release number and year, classification ID (composed of 8 digits), the most recent classification change ID (composed of 8 digits), parent classification name, change status, and proposal documents [5].
However, in our web-based system, the current ICTV database was redesigned and divided as the tables in our database (Table 3). Specifically, to enhance the database and to make useful linkages for NCBI accession, the NCBI Taxonomy items described in Table 3 and the items parsed by web scraping were built as an “ICTV history” table and “ICTV Taxonomy” table in Table 3, respectively. The “2016 ICTV Species” table consists of the data parsed by the ICTV Master Species List (2016, v1.3).
Web construction
Our web-based system includes the traditional taxonomy (order, family, subfamily, genus, and species), as well as the information regarding strain and isolate. Furthermore, users can easily access journals containing information related to the published virus GenBank via the EMBL RESTful protocol [6] and directly download and reuse NCBI FASTA and “gbk” file via the Entrez openAPI [7]. However, the information of the chosen PubMed and strain and isolate are based on NCBI accession in (Table 3). The journal search is connected by the parameters of the HTML get method, which is indicated by the PubMed ID. Web scraping methods were used to build the “ICTV history” table in our database after extracting meaningful information from the NCBI raw data. The tables in our database form the foundation of the web system. In the Spring framework, the web system consists of Java, which is independent of the operating system. According to the user commands, the internal parsing process is executed by pipelines that are implemented by the BioPython module. The internal parsing process extracts the information of the virus taxonomy, history, and reference articles from XML data, which are produced by the EMBL RESTful API, and text files of the NCBI virus GenBank. The overall process map for the web system is described in Fig. 2.
Results and Discussion
The aim of this study was to evaluate and develop a computerized system that is fused with bioinformatics. Specifically, we focused on implementing an environment that extends the capabilities of the ICTV web system and connects to PubMed in order to enhance searches performed by academic groups. We extended and rebuilt the database and extracted meaningful data using a pipeline that parses XML, text, and web contents. Henceforth, this computerized system will be continually extended and used as a web tool that can detect new viral types and classify them rapidly and accurately. Recently, a new virus classification system based on metagenomics has been proposed. Thus, web-based virus taxonomy could augment the quality by adding virus classification, which is derived by viral metagenomics analysis [8]. We suggest that the web system, analytical pipelines, and extended database we describe herein could be used to add these metagenomics data to ICTV taxonomy data.
Supplement. Detail description of ICTV Extension DB
Supplementary data can be found with this article online at https://doi.org/10.5808/GI.2018.16.4.e22.