Introduction
Functional annotation of putative proteins is a fundamental and essential practice in the postgenomics era [1]; it allows us to analyze genomic and genetic features, such as physiological activity and metabolism, as well as to discover medically and industrially relevant enzymes. Since large numbers of putative proteins were discovered from a vast amount of sequencing data generated using high-throughput sequencing technologies, including those of the next and third generation, many automated functional annotation systems have contributed greatly to the annotation of them with minimal manual effort [2]. However, their runtime performance of functional annotation against large extant databases often causes a bottleneck, and especially, standalone tools, such as AutoFACT [3] and BLANNOTOR [4], demand high-performance hardware resources for fast annotation from users.
From the user's perspective, a web-based annotation server system would be a useful tool to bypass the demands of high-performance computer resources, and besides, they offer user-friendly interfaces. The RAST server system is particularly popular and can be used to rapidly annotate many microbial proteins against a specially curated subsystem database [5]. Web server systems, however, may be undesirable because of critical obstacles, such as the limitation of usable server resources, a long waiting time by many queries, a low-bandwidth network or unstable traffic flow associated with the upload of query data and download of outputs, and data security problems. Thus, some users prefer standalone systems to web-based systems in spite of the demand for high-performance resources. Although standalone and web-based systems have good and bad points, slow runtime performance in themselves cannot be avoided because of the exponential increase in database sizes, without controlling some aspect of the annotation workflow.
We developed SFannotation, which rapidly annotates putative proteins by using single or bidirectional best-hit approach with sequence-based methods-BLASTP [6] and HMMSEARCH [7]-against big extant databases: Swiss-Prot [8], TIGRFAMs [9], Pfam [10], and the non-redundant sequence database (NR) of NCBI [11]. As best-hit approaches, especially bidirectional best-hit [12], have been widely utilized in searching reliable homologous protein sequences, such as orthologs, as well as functional annotation systems [13,14,15,16], SFannotation can reliably annotate putative proteins. Remarkably, SFannotation can rapidly annotate proteins against large extant databases by our hierarchical workflow.
Methods and Results
Before annotating putative proteins against Swiss-Prot, TIGRFAMs, Pfam, and the NR database, SFannotation filters out all proteins described in the databases by terms, such as "unknown," "hypothetical," "unclassified," "uncharacterized," "putative," "predicted," and "conserved" (Fig. 1A), because some putative proteins may be misannotated by their inclusion. Then, using BLASTP and HMMSEARCH, SFannotation searches homologous proteins and domains in each refined database using a default threshold (≤10-5 E-value) and selects the highest-scoring homolog to annotate putative proteins as the best-hit approach, such as single best hit and bidirectional best hit [12, 16].
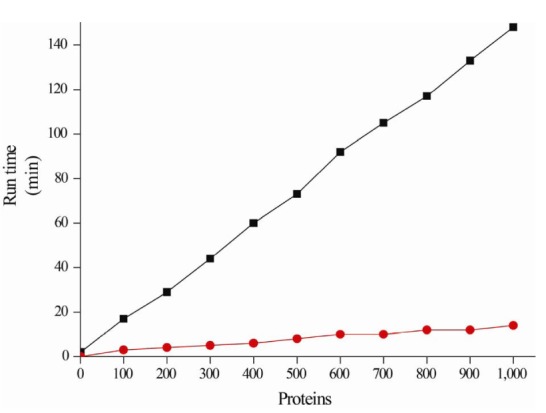
Putative proteins are hierarchically annotated using the following database priority: Swiss-Prot → TIGRFAMs → Pfam → NR, which is ordered according to their reliability (Fig. 1B). Once annotated, the putative proteins are no longer queried using homology searches against the other databases. For example, if a putative protein is annotated against Swiss-Prot, it is excluded from annotation against the other databases, while the remaining unannotated putative proteins continue to be annotated against the other databases. Therefore, the runtime performance can be reduced, because the number of unannotated putative proteins gradually decreases (Fig. 2).
Implementation
SFannotation is written in Perl and bash shell and is implemented on a Linux/Unix system on which BLASTP and HMMSEARCH are able to function. SFannotation automatically annotates putative proteins with downloading of all four databases, as well as BLASTP and HMMSEARCH. SFannotation is implemented by a command line on the Linux/Unix system: "perl SFannotation --download --fasta <input fasta file> --speedup" (Supplementary Fig. 1).