Introduction
Colorectal cancer (CRC), also called colon cancer or large bowel cancer, includes cancerous growths in the colon, rectum, and appendix [1]. With 655,000 deaths worldwide per year, it is the fourth most common form of cancer in the United States (US) and the third leading cause of cancer-related deaths in the western world [1, 2]. In Korea, CRC is one of the most commonly diagnosed cancers, and its incidence is now dramatically increasing with the westernization of lifestyles [3]. According to statistics for Korea, the incidence of CRC was 9.8 per 100,000 men and 10.4 per 100,000 women from 1999-2001 [4]. These incidence rates for CRC increased to 18.2 per 100,000 men and 13.7 per 100,000 women in 2003 [5].
Given the high incidence of CRC and its significant cost to society, the ability to accurately predict the possibility of developing the disease using identifiable risk factors may help both physicians and patients prevent its occurrence [6]. Numerous studies have identified risk factors related to CRC, such as age, sex, family history of CRC, smoking, physical activity, aspirin/nonsteroidal anti-inflammatory drug (NSAID) use, vegetable intake, body mass index (BMI), alcohol consumption, and hormone replacement therapy by women [7-10].
Recently, there have been a number of studies that developed a risk score or a prediction model of certain diseases, such as coronary heart disease (CHD) and cancers, using these identified risk factors [11, 12]. However, these risk scores or prediction models have excluded genetic risk factors. Genetic polymorphisms contributing to certain disease incidences, such as CHD, could be one type of emerging risk factor under investigation in studies generally focused on a priori selected candidate genes [13, 14]. Advances in genome technologies have made it possible to genotype and evaluate many single-nucleotide polymorphisms (SNPs) throughout the human genome to identify novel disease susceptibility genes [15].
A CRC prediction model has been developed in a previous study that estimates the probability of developing CRC, given a specific age, risk factor profile, and time period in white men and women aged 50 years and older [16]. However, genetic polymorphisms have not been included in the study. Another prediction model, developed among middle-aged Japanese men, included conventional risk factors without genetic risk factors [17]. A recent study developed a prediction of CHD risk, aggregating information from multiple SNPs into a single genetic risk score (GRS) and determined an improvement in the prediction of incident CHD in the Atherosclerosis Risk in Communities (ARIC) study [18].
From recent studies, several SNPs that may play an important role in triggering CRC have been introduced by a genome-wide association study (GWAS) among whites, Japanese, and Chinese but not Koreans [19-22]. Moreover, prediction models that were developed recently were performed among whites and the Japanese population [16, 17]. Previous studies have shown that combining multiple loci with modest effects into a global GRS might improve the identification of persons who are at risk for common complex diseases [23-25]. Therefore, in this study, we intended to describe a GRS by aggregation of multiple SNPs contributing to CRC through a GWAS. Furthermore, we aimed to develop a prediction model consisting of conventional risk factors as well as a genetic risk factor, such as GRS, in Koreans in the Korean Cancer Prevention Study-II (KCPS-II).
Methods
Study population
The initial study population included 200,595 individuals, 20-77 years of age, who visited 16 health promotion centers nationwide from April 2004 to December 2007 in the KCPS-II. Of these, there were 325 confirmed cases of CRC [26], but 132 cases Ōēź55 years of CRC onset age were excluded to obtain early-onset CRC cases. For controls, they were recruited from the Korean Metabolic Syndrome Research Initiative study, a part of KCPS-II, in Seoul, initiated in December 2005. A total of 9,128 individuals were recruited in 2006, and an additional 17,569 individuals were recruited in 2007. Therefore, the total Seoul cohort included 26,697 volunteers. Volunteers from the first round had routine health examinations at the Health Promotion Center in university hospitals between January 2006 and December 2007. From this total, 1,004 individuals were genotyped using Affymetrix Genomewide Human SNP Array 5.0 (Affymetrix, Santa Clara, CA, USA). However, 10 of 1,004 individuals were removed because of low genotyping call rates (<95%), and 4 individuals were shown to have biological relatives; so, one member of each pair was excluded. Eleven and 2 individuals were also excluded as a result of gender mismatches [27]. An additional 6 cases and 1 control were excluded due to missing anthropometric measurements (height, weight, BMI, waist circumstance [WC], and blood pressure [BP]) and self-reported questionnaire information (smoking status and alcohol consumption). A detailed description of the KCPS-II study design and methods of selection of controls in this study are published elsewhere [27]. Therefore, a total of 1,163 participants (men, 687; women, 476) were included in this study: 187 cases (men, 133; women, 54) and 976 controls (men, 554; women, 422). A written consent form was signed by all study participants, and the Institutional Review Board of Yonsei University approved the study protocol.
Genotyping
DNA samples were isolated from the peripheral blood of participants and genotyped using Affymetrix Genomewide Human SNP Array 5.0 (Affymetrix Inc.) at DNA Link Inc. (Seoul, Korea). Internal quality control (QC) measures were employed to ensure accuracy of the data. The QC call rate (dynamic model algorithm) was Ōēź95%, and heterozygosity of X chromosome markers identified the gender for each sample. Genotype calling was performed by Birdseed (v2) algorithm. Chromosome Y was not analyzed. A total of 1,163 individuals were genotyped via this platform in the analysis. PLINK (v1.07) was used to estimate identity by state (IBS) over all SNPs [28]. A default set of 426,019 SNPs was used for further analysis, as recommended by Affymetrix. In the quality assurance screening, we flagged SNPs with genotype call rates < 95%, minor allele frequencies < 0.01, and SNPs showing deviation from Hardy-Weinberg equilibrium (HWE) at p < 0.0000001. The final set of acceptable markers included 312,506 autosomal SNPs. Accuracy of the genotyping was calculated by Bayesian robust linear modeling using the Mahalanobis distance (BRLMN) algorithm [29].
Chemistry and anthropometric measurements
Serum, separated from peripheral venous blood, was obtained from each participant after a 12-h fast and then stored at -70Ōäā until analyzed. For anthropometric measurements, WC was measured on exposed waists midway between the lower rib and the iliac crest using a measuring tape. For difficult cases, WC was measured at 3 cm above the navel. Weight and height were measured while participants were wearing light clothing. BMI was calculated as weight (kg) divided by height squared (m2). Both systolic and diastolic BP was measured after a 15-min rest. In addition, each participant was interviewed using a structured questionnaire to collect information on smoking and alcohol consumption as well as demographic characteristics, such as age, gender, and family and past history of clinical diseases. Cigarette smoking was classified into never smokers, ex-smokers, and current smokers. Alcohol consumption was divided into nondrinkers and current drinkers. Regular physical activity was tracked as either "yes" or "no".
SNP selection and GRS calculation
In the association of SNPs with CRC, the SNPs with p < 10-5 in Korean men were: rs17391002 (CXCL12), rs9549448 (SOX1), rs254833 (MYO10), rs2553614 (TMEM71), rs13153032 (NSUN2), rs2288073 (FLJ30851), rs9604214 (SOX1), rs9865670 (OPA1), rs17186320 (KIAA1009), rs1509497 (RFX8), rs235428 (PHF20L1), rs9845920 (OPA1), rs9846212 (OPA1), rs6763744 (OPA1), rs4128317 (ALK), rs7646304 (OPA1), rs17047306 (SPATA17), rs1490338 (SPATA17), rs902351 (SPATA17), and rs2543662 (ITSN2) (Supplementary Table 1). The SNPs with p < 10-5 in Korean women in the association between SNPs and CRC were: rs10083736 (GOT2), rs16987827 (DHX35), rs8046516 (GOT2), rs9926182 (GOT2), rs17523778 (FAM174B), rs4974411 (TPRA1), rs1834902 (H2AFY), rs16895308 (MAST4), rs8032832 (FAM174B), rs6901560 (PD6), rs11025480 (PRMT3), rs3814110 (BNC2), rs16895307 (MAST4), rs7089063 (MARCH8), rs16893688 (IBTK), rs6861487 (MAST4), rs9613463 (MN1), rs11242237 (H2AFY), rs11150094 (WWOX), and rs9625253 (MN1) (Supplementary Table 2). Each SNP in this study was assumed to be associated with risk according to an additive genetic model, which performs well, even when the true genetic model may not be known or may be incorrectly specified [30].
A GRS was calculated on the basis of reproducible tagging of SNP-associated loci reaching genomewide levels of significance. In this study, the GRS was calculated with the 3 SNPs in Korean men and 5 SNPs in Korean women showing the strongest association with CRC (p < 10-6). The GRS was created by two methods: a simple count method (count GRS) and a weighted method (weighted GRS) [31, 32]. Both methods anticipated each SNP to be independently associated with risk. We assumed an additive genetic model for each SNP, applying a linear weighting of 0, 1, or 2 to genotypes containing 0, 1, or 2 risk alleles, respectively. This model is known to perform well, even when the true genetic model is unknown or wrongly specified [30]. The count model assumes that each SNP in the panel contributes equally to the risk for CRC and was calculated by summing the values for each of the SNPs. The weighted GRS was calculated by multiplying each beta-coefficient by the number of corresponding risk alleles (0, 1, 2).
Outcome classification
The principle outcome variables were prevalence (n = 165) and incidence rates (n = 22), based on national cancer registry and hospitalization records. Although Korea has a national cancer registry, reporting was not complete during the time of follow-up, and consequently, hospital admission files were used to identify first admission events for CRC. An incident of CRC was coded as occurring, based on either a positive report from the national cancer registry or upon hospital admission for a cancer diagnosis [33]. According to the International Classification of Diseases, Tenth Revision (ICD-10), CRC was coded as C18-C20 [34].
Statistical analysis
All analyses were conducted using PLINK version 1.06 (Free Software Foundation, Inc., Boston, MA, USA) and SAS statistical software version 9.0 (SAS Institute Inc., Cary, NC, USA). All statistical tests were two-sided, and statistical significance was determined as p < 0.05. To evaluate general characteristics of the study population, means and standard deviations (SD) were calculated, and frequency of cigarette smoking, alcohol consumption, and physical activity was determined. Paired t-tests were performed to indicate the differences between case participants and control participants for both men and women. A X2 goodness-of-fit test was used to assess whether SNPs were in HWE and to determine differences in genotype frequencies between CRC cases and controls. The GRS was categorized into quartiles. The CRC risk associated with genotype was estimated as s ORs and 95% confidence interval (CI), computed using logistic regression with an additive genetic model. We also used receiver operating characteristic (ROC) curve analysis and calculated the area under the curve (AUC; also known as the C statistic) to evaluate the discrimination power of the model. In addition, internal validity of each model was checked using bootstrap [35], while 10-fold crossvalidation was used for the external validity of each model (Supplementary Tables 3 and 4) [36].
Results
Our analysis included 687 men (cases, 133; controls, 554) and 476 women (cases, 54; controls, 422), 20-77 years of age. The number of prevalent cases of CRC identified was 166. An additional 22 incident cases of CRC occurred during follow-up. Table 1 details the general characteristics of case participants and control participants at baseline. The mean age (SD) was 42.9 (┬▒ 8.7) years for the study population-43.5 (┬▒ 8.9) for men and 42.0 (┬▒ 8.4) for women, respectively. No significant differences were observed in BMI, WC, systolic BP, or diastolic BP among case participants and control participants for both men and women (p > 0.05); however, case participants were older and had a family history of CRC more than control participants in both men and women (p < 0.001).
Table 2 indicates the area under the ROC curves for models that included both conventional risk factors and a genetic risk factor, GRS, compared with the AUC for the model that included only conventional risk factors. In the prediction model of CRC, we included age and family history of CRC as conventional risk factors and counted GRS or weighted GRS as genetic risk factors. For both men and women, including the GRS in the model increased the AUC over that observed when the AUC was based on only age or age and family history of CRC. For men, the AUC (95% CI) was 0.729 (range, 0.682 to 0.767) for conventional risk factors plus counted GRS (p < 0.001) and 0.719 (range, 0.677 to 0.761) for conventional risk factors plus weighted GRS (p < 0.001). The AUC (95% CI) was 0.692 (range, 0.647 to 0.732) for conventional risk factors alone. The increase in the AUC for the model with counted GRS was 0.042 and 0.032 for the model with weighted GRS. For women, the AUC (95% CI) was 0.650 (range, 0.615 to 0.680) for conventional risk factors plus counted GRS (p < 0.001) and 0.646 (range, 0.612 to 0.674) for conventional risk factors plus weighted GRS (p < 0.001). The AUC (95% CI) was 0.603 (range, 0.569 to 0.637) for conventional risk factors alone. The increase in the AUC for the model with counted GRS was 0.052 and 0.048 for the model with weighted GRS.
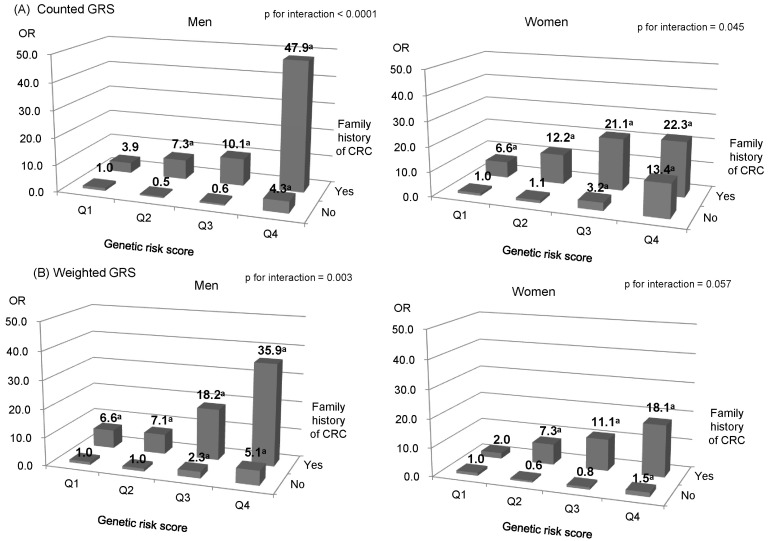
We further examined the association between GRS and CRC risk for both men and women in the KCPS-II, with stratification by family history of CRC (Fig. 1). The interaction between counted or weighted GRS and family history of CRC was significant in men, indicating a stronger genetic effect among participants with a positive family history of CRC than in those without it (p for interaction < 0.05) (ROC, 0.834 for counted GRS; ROC, 0.822 for weighted GRS). Women with a positive family history of CRC in the highest quartile of weighted GRS had an OR of 22.3 (95% CI, 1.4 to 344.2) and 18.1 (95% CI, 3.7 to 88.1) compared to those without a family history of CRC and counted or weighted GRS in the lowest quartile, respectively (ROC = 0.826 for counted GRS; ROC = 0.818 for weighted GRS). However, they were not statistically significant (p for interaction > 0.05). In addition, smoking, alcohol consumption, BMI, and WC did not interact significantly with GRS (data not shown).
Discussion
This study evaluated the ability of the GRS, which aggregates information from multiple genetic variants, to improve the prediction of CRC risk beyond the prediction risk afforded using conventional risk factors. For both men and women, inclusion of counted GRS or weighted GRS increased the AUC by 0.5% to 4.2% beyond the AUC provided by conventional risk factors, such as age and family history of CRC. Men with a positive family history of CRC and GRS in the highest quartile were determined to have a statistically significant increased risk of CRC than those without a family history of CRC and GRS in the lowest quartile. However, women with a positive history of CRC and GRS in the highest quartile were determined to have an increased risk of CRC than those without a family history of CRC and GRS in the lowest quartile, but this result was not statistically significant.
CRC is a multifactorial disease involving a variety of elements, leading to the development of clinical manifestations [37]. This recognition had led to the development of risk assessment tools that attempt to synthesize the values of numerous variables into a single statement regarding the risk of developing cancer [38]. In this study, 20 SNPs were respectively genotyped in Korean men and women. Among these SNPs, 3 SNPs in Korean men and 5 SNPs in Korean women showing the strongest association with CRC were used for the calculation of GRS. The GRS was calculated using a linear weighting of 0, 1, or 2 for genotypes containing 0, 1, or 2 risk alleles, respectively. The weighted GRS was computed by multiplying each beta-coefficient by the number of corresponding risk alleles. However, when multiplying each beta-coefficient by the number of corresponding risk alleles, negative values of beta-coefficients may be obtained in some genotypes of the SNPs. Therefore, it may affect the OR values for CRC when compared to the OR values for CRC determined using counted GRS. Still, the calculation results of both counted GRS and weighted GRS were similar to each other.
Cornelis et al. [31] and Ripatti et al. [32] used methods similar to the GRS created for our study. Several other studies have reported different ways of calculating risk scores for the prediction of diseases [39-41]. Horne et al. [39] introduced a regression method for calculating risk scores that incorporated 3 genetic polymorphisms and other risk factors and found that the frequency of coronary heart disease was different at different regression score levels. Ortlepp et al. [40] concluded that multiple SNPs are better than single SNPs and that as many as 200 SNPs may be necessary for "reasonable" genetic discrimination. Aston et al. [41] suggested that a score based on 90 SNPs in 78 genes can predict the risk of breast cancer, but the identity of the SNPs and the algorithm for calculating the score remain proprietary. An alternative way to calculate GRS using machine approaches, such as support vector machines (SVMs), could be introduced, as SVMs have already been used to deal with many biological problems, such as DNA expression profiles [42]. Still, further studies are needed to use machine learning approaches, such as SVMs, for the calculation of GRS. To our knowledge, there have been no studies evaluating a GRS using SNPs contributing to CRC for the prediction of the disease in the Korean population.
The present study evaluated a prediction model using counted GRS or weighted GRS together with conventional risk factors, such as age and family history of CRC among Koreans. The risk of CRC is said to increase in individuals with a family history of CRC, in particular those >50 years of age [43, 44]. From a recent study, a CRC prediction model was developed with known major risk factors of age, BMI, alcohol consumption, smoking status, and physical activity level for middle-aged Japanese men [17]. Another recent study on the prediction model of CRC included an individual's age, sex, history of CRC, sigmoidoscopy/colonoscopy, polyps, family history of CRC, smoking, physical activity, aspirin/NSAID use, vegetable intake, BMI, and hormone replacement in women [16]. In our study, the prediction model of CRC was comprised of conventional risk factors, such as age and family history of CRC, together with the GRS. As determined, inclusion of counted GRS or weighted GRS revealed improved estimates of CRC prediction beyond that provided by conventional risk factors, such as age and family history of CRC. For example, when counted GRS were added to the prediction model of CRC consisting of age and family history of CRC, the AUC increased by 4.2% in men and 5.2% in women, whereas the AUC increased by 3.2% in men and 4.8% in women when weighted GRS were added to the same model. Studies showing significant relationships of GRS in conjunction with coronary heart disease, type 2 diabetes, and breast cancer have reported that considering the contribution of multiple SNPs may improve the predictive value of GRS for such diseases [18, 31, 45]. In other words, combining multiple loci with modest effects into a global GRS might improve identification of persons who are at risk for such diseases [23-25]. For example, in the ARIC study, the contribution of multiple SNPs into a single GRS was responsible for an improvement in the prediction of incident CHD [18]. In a study that used counted GRS or weighted GRS to determine the risk for type 2 diabetes in US men and women, individuals in the highest quintile of GRS had a significantly increased risk of type 2 diabetes compared to those in the lowest quintile; however, the addition of GRS increased the AUC by only 1%. In this instance, the GRS was determined to be useful when combined with the joint effects of BMI and counted GRS or family history of diabetes and counted GRS [30]. In our study, individuals in the highest quartile of GRS had increased risk of CRC compared to those in the lowest quartile of GRS for both men and women. In addition, in strata of family history of CRC and GRS, this increase was even higher in individuals with a family history of CRC in the highest quartile of GRS compared to those without a family history of CRC in the highest quartile of GRS in both men and women. Still, there were statistically significant interactions in men but not in women. In this study, the most commonly used conventional risk factors, such as smoking and alcohol consumption, were also not included in the prediction model of CRC, as smoking, alcohol consumption, BMI, and WC did not significantly interact with the GRS. Therefore, further studies are needed to verify these results.
A family history of CRC is commonly used as a surrogate marker for determining genetic susceptibility to CRC and remains one of the strongest risk factors for the disease [10, 31, 46]. Approximately 25% of all CRC cases occur in individuals with a family history of the disease and no genetic disorders [47]. In addition, some retrospective studies have suggested that a history of CRC in a first-degree relative (a parent or sibling) elevates a person's lifetime risk of CRC from 1.8-fold to 8.0-fold [10, 47]. This family history risk factor may encompass both genetic and shared environmental components [31]. In our study, after controlling for age and GRS, the strong relationship between family history of CRC and risk of CRC persisted. These findings suggest that other risk loci remain to be discovered or that family history has a much larger shared environmental component than previously thought [31].
Our study was not without limitations. The cross-sectional design precluded the determination of causality, and a prevalent case bias may exist due to the higher number of prevalent cases (n = 165) of CRC included compared to the number of incident cases (n = 22). Combining prevalence and incidence cases could introduce survival biases. Still, the 5-year survival rate for CRC in Koreans was 71.3% in 2009 while that in Americans, Europeans, and Japanese was 65.0%, 56.2%, and 65.2%, respectively [43]. It could be said that Koreans have higher survival rates for CRC compared to other ethnic populations. Additionally, this study is also a case-cohort study. Blood samples of prevalent cases used in this study were from baseline, and incidence cases during the follow-up period, suggested as prevalent cases in this study, might have been missed, as other blood samples were not taken. Therefore, those prevalent cases at baseline might have become incident cases or mortality cases during the follow-up period. It is hard to say if this study was performed among survivors. Another limitation included a self-reported family history of CRC, thus precluding the definitive exclusion of potential misclassifications. The statistical power of the current study might be too low, as genotyping was performed separately for men and women. In addition, performing multiple tests separately in both men and women may increase error rates. Although CRC affects men and women equally, gender differences in CRC may exist. For example, regarding colorectal polyps and tumors, men had a greater risk of polyps (OR, 1.52; 95% CI, 1.41 to 1.64) and tumors (OR, 1.43; 95% CI, 1.22 to 1.68) than women. In addition, women had greater number of purely right-sided polyps and tumor development [48]. Therefore, detection of genetic effects separately in men and women may be needed. In addition, age differences in case and control participants may also increase error rates, as control participants may become CRC patients when they reach the case age. This study also involved the lack of validation and replication of the current study results. Therefore, it is hard to say that there may have been a true association between GRS and CRC in Korean men and women. However, bootstrapping and 10-fold cross validation were used for internal and external validity of this current study. Furthermore, although sigmoidoscopy/colonoscopy history was the strongest risk factor in the previous study, this current study did not include it as one of the conventional risk factors of CRC. Cases included in this study were also relatively small. This study also excluded cases Ōēź 55 years of CRC onset age to obtain early-onset CRC cases. Therefore, estimate effects of cases Ōēź 55 years of CRC onset age were hard to be seen in this study. Finally, most SNPs found to be associated with CRC among the study population were not similar to those SNPs found in relation to CRC among other populations. It also could be due to differences in ethnic population and the ages of case participants included in this study (cases < 55 years). Nevertheless, this relatively large-scale study demonstrated the effectiveness of the prediction model of CRC using the GRS consisting of only SNPs that associated significantly with CRC and evaluated the effects on the risk for CRC in combination with conventional risk factors, such as family history of CRC, with the GRS. Moreover, the present study included the Korean population, whereas previous studies involving CRC prediction models using conventional risk factors or the relationship of genetic risk factors to CRC were limited to white and Japanese populations [17, 20-22].
In conclusion, our findings suggest that the prediction model of CRC revealed improved prediction estimates when age, family history of CRC, and the GRS in the Korean population were included. Furthermore, when compared to those in the lowest quartile of GRS in the presence or absence of a family history of CRC, the risk of CRC was found to be significantly increased in individuals with a family history of CRC in the highest quartile of GRS. However, it was statistically significant in men but not in women. Findings in this current study might provide a small piece of evidence in prediction of CRC for reducing its prevalence and incidence rates. The prediction model developed in this study needs to be validated or replicated in an independent population. Therefore, further studies are needed to be applied to the general population.