Introduction
Hepatitis is inflammation of the liver, most commonly caused by a viral infection [1]. Five main hepatitis viruses are known, referred to as types A, B, C, D, and E. We are concerned with these main types because of the burden of illness and death; they also have the potential for outbreaks and epidemic spread. In particular, types B and C lead to chronic disease in hundreds of millions of people and together constitute the most common cause of liver cirrhosis and cancer [1]. The Korean Health Insurance Review and Assessment Service [2] reported on C type hepatitis patients in Korea, described in Table 1. Table 1 shows that the number of patients has been increased steadily. The prevalence rate of hepatitis type C in Koreans is 1%-1.5%. From the prevalence rate, 500,000-600,000 patients are estimated. Only 10% of them are treated. If we find risk factors for hepatitis, it is helpful for the prevention and treatment of hepatitis.
In this study, we performed a genome-wide association study of hepatitis in Korean populations. We tried to find significant single-nucleotide polymorphisms (SNPs) and epidemiological traits related to hepatitis.
Methods
Phenotype and genotype data
The study subjects are based on the Anseong and Ansan cohort data, part of the Korea Association Resource (KARE) projects. The genotypes and phenotypes of the cohort population are described in Cho et al. [3]. Subjects with genotype accuracies below 98%, high missing genotype call rates (Ōēź4%), high heterozygosity (>30%), or inconsistency in sex were excluded from subsequent analyses. Individuals who had a tumor were excluded, as were related individuals whose estimated identity-by-state values were high (>0.80). After these quality control steps, 352,000 SNP genotypes for 8,842 individuals were selected [4]. The epidemiological trait data for these individuals were also from the KARE project. Among the total of 8,842 individual cases, 368 had hepatitis with age over 30, and 1,500 controls were randomly selected from non-hepatitis individuals with age over 30. Table 2 summarizes the clinical characteristics of the phenotypes in this study.
The chosen dataset was imbalanced; the number of cases was smaller than controls. A dataset is imbalanced if it contains many more samples from one class than from the rest of the classes [5]. In this case, the classification analysis showed good accuracy in the majority class but very poor accuracy in the minority class. Therefore, we needed to transform the imbalanced dataset to a balanced dataset. We applied an 'oversampling' scheme [5] to overcome the imbalance problem. The final dataset contained 1,500 controls and 1,500 cases.
Statistical analysis
To find significant SNPs, we used PLINK, version 1.07 [6]. Other statistical analyses were performed using R, version 3.1. We used logistic regression to find major factors related with hepatitis. Receiver operating characteristic (ROC)/area under the curve (AUC) analysis was performed to confirm the prediction power of the major factors that were found.
Results
Genome-wide association studies
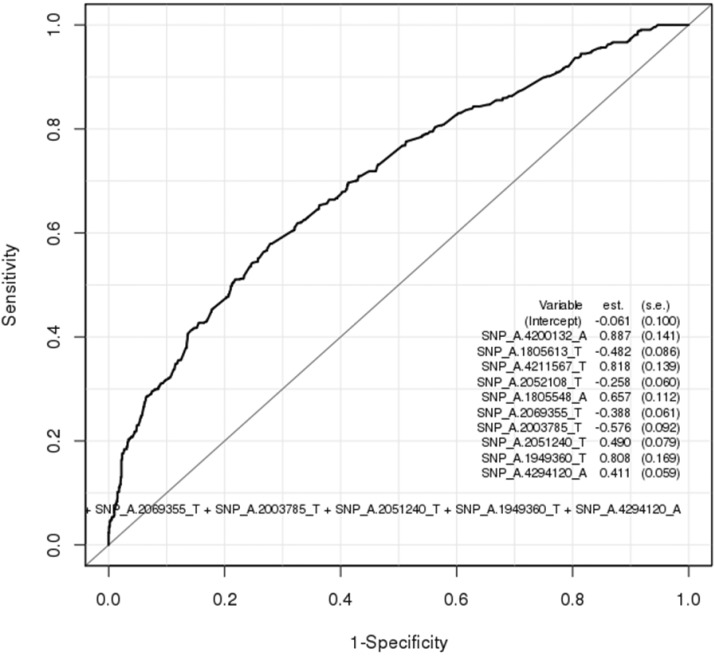
Table 3 summarizes 20 SNPs that were top-ranked by p-value in the genome-wide association analysis. Unfortunately, there were no significant SNPs that met p < 5 ├Ś 10-8. We performed logistic regression test on the top-ranked SNPs, and we took 10 SNPs in Table 4. Logistic regression measures the relationship between a categorical dependent variable (phenotype) and one or more independent variables (SNPs). Fig. 1 shows the ROC plot for the classification test using the 10 SNPs. The AUC value from the ROC plot is 0.700; it is not enough as a biomarker.
Epidemiological studies
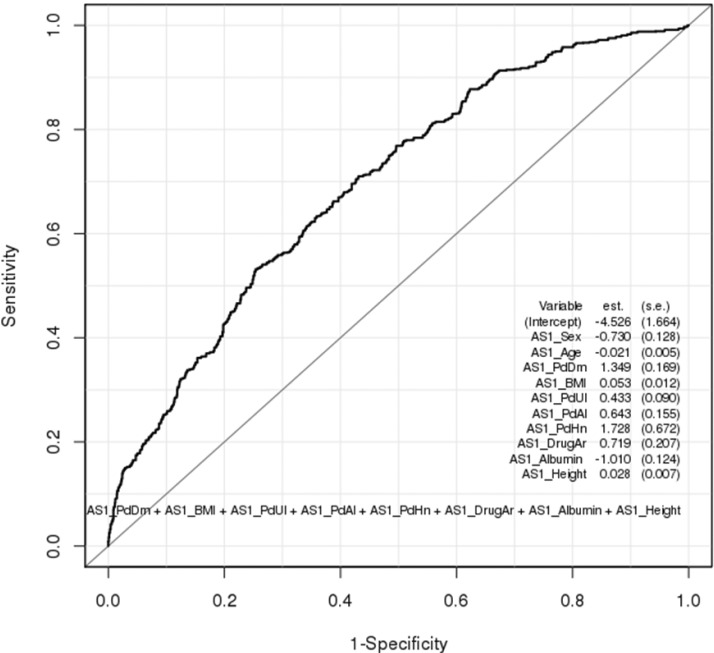
Using the traits in Table 2, we performed a logistic regression test. Table 5 summarizes the results. As we can see, diabetes, gastritis, allergy, external head injury, taking arthritis drug, and degree of albumin were highly correlated with hepatitis. In the case of diabetes, the probability that a diabetes patient had hepatitis was 4 times higher than a diabetes-free person. In general, the hepatitis C virus is often associated with diabetes, and some diabetics may even develop chronic hepatitis [7]. Gastritis is influenced by hepatitis. If we have hepatitis, the probability of getting gastritis is increased 1.5 times. Especially, chronic gastritis develops by chronic hepatitis [8]. Sometimes, allergy cahepatitis. It increases the probability of hepatitis by 1.8 times. Hepatitis virus can cause arthritis [9]; it increases the probability of arthritis by 1.9 times. The degree of albumin is inversely proportional to hepatitis (odds ratio [OR], 0.8), because the liver makes albumin, and hepatitis enervates the process. The OR between external head injury and hepatitis is very high (OR, 1.31). We cannot explain the medical relationship between them. It needs more analysis.
Discussion
From the epidemiological analysis, we found relevant variables with hepatitis. We confirmed that hepatitis has a wide relation with other diseases. If we make a disease network in which the node is a disease and the edge is a correlation coefficient between two nodes, we can understand the relationship among diseases more clearly. Current known disease networks [10, 11] do not show detailed relationships between hepatitis and other diseases. This is a future research topic.
KARE data are the result of a cohort study. It contains a small number of samples for specific diseases, whereas the whole population is very big. It induces an imbalanced dataset for statistical analysis. Our study implies a basic limitation, even though we tried to complement the problem. We also did not find any significant SNPs related with hepatitis. If we combine the knowledge of other biological databases, we may get a more meaningful interpretation for the results of our experiment.