Accelerating next generation sequencing data analysis: an evaluation of optimized best practices for Genome Analysis Toolkit algorithms
Article information

Abstract
Advancements in next generation sequencing (NGS) technologies have significantly increased the translational use of genomics data in the medical field as well as the demand for computational infrastructure capable processing that data. To enhance the current understanding of software and hardware used to compute large scale human genomic datasets (NGS), the performance and accuracy of optimized versions of GATK algorithms, including Parabricks and Sentieon, were compared to the results of the original application (GATK V4.1.0, Intel x86 CPUs). Parabricks was able to process a 50× whole-genome sequencing library in under 3 h and Sentieon finished in under 8 h, whereas GATK v4.1.0 needed nearly 24 h. These results were achieved while maintaining greater than 99% accuracy and precision compared to stock GATK. Sentieon’s somatic pipeline achieved similar results greater than 99%. Additionally, the IBM POWER9 CPU performed well on bioinformatic workloads when tested with 10 different tools for alignment/mapping.
Introduction
As the price of next generation sequencing (NGS) decreases and the data footprint increases, compute power is a major limitation. The bioinformatics processing of NGS data is routine in many translational research and precision medicine efforts with the Genome Analysis Toolkit (GATK) from the Broad Institute and their “Best Practices” workflows [1-3] being widely accepted as standards for germline and somatic short variant discovery.
The majority of computational algorithms specific for NGS were developed for use in a CPU environment with standard threading techniques. However, as NGS becomes more routine, the need to offer faster processing is essential. Despite the fact that x86_64 (henceforth x86) CPUs from Intel represent the most common processing architecture in both the server space as well as desktop workstations, alternative architectures exist which offer some advantages such as POWER9 from IBM and GPUs from NVIDIA.
This article compares the speed, accuracy, and scalability of the official GATK algorithms running on Intel x86 CPUs, a POWER9 optimized version provided by IBM, a GPU optimized version provided by Parabricks, and an x86 optimized version provided by Sentieon [4]. Additionally, the ability of POWER9 CPUs to handle bioinformatic workloads is assessed by comparing the performance of a number of other bioinformatic tools compiled to run on both x86 and POWER9 systems.
Methods
Hardware configuration
All x86 jobs were run on an HPC cluster node (Thinkmate HDX XB24-5260V4) powered by two 8-core Intel Xeon E5-2620 v4 CPUs and 256GB ECC memory. All POWER9 jobs were run on an HPC cluster node (IBM AC922) powered by two 16-core POWER9 CPUs (Part #02CY417), 512GB ECC memory, and four Nvidia TESLA V100 GPUs each with 32GB HBM2 memory. Disk I/O was handled via a DDN storage appliance connected to each node via InfiniBand.
Software configuration
Job scheduling on the HPC cluster was handled by SLURM. GATK software was run with parameters according to their best practices workflows with performance optimizations found by Heldenbrand et al. [5] with any deviations indicated as such. The Sentieon and Parabricks pipelines were run according to their included documentation. Runtimes were calculated using the GNU time utility.
Sensitivity and precision calculations
GATK’s Concordance tool was utilized to compare the tested Variant Call Format (VCF) outputs to different reference VCFs depending on the comparison being made. The reference VCF is treated as a truthset, and the number of true-positive, false-positive, and false-negative variants in the query VCF are counted. Sensitivity is calculated as true-positives/(true-positives + false-negatives). Precision is calculated as true-positives/(true-positives + false-positives).
POWER9 testing workloads
For the RNA sequencing (RNAseq) benchmarks with STAR v2.7.0c [6], Tophat v2.1.1 [7], HISAT2 v2.1.0 [8], and BBMap v38.34 [9], 15 paired end RNAseq libraries were downloaded from the ENA database (Study PRJEB23554). FASTQ files trimmed via BBDuk before being mapped to GRCh38 using each tool’s default settings. For BBMap and Tophat only one library was used for benchmarking, while HISAT2 and STAR performed mapping using all 15. For the splice aware aligners, STAR, HiSat2, and Tophat, the Gencode v29 annotation GTF file was used.
For the DNA short read mapping benchmarks with BWA MEM v0.7.17-r1188 [10], Bowtie v1.2.2 [11], and Bowtie2 v2.3.5.1 [12], the NA12878 50x WGS library was used. The FASTQ files were mapped to GRCh38 using each tool’s default settings.
For blastx v2.8.1 [13], all Brachypodium distachyon transcript sequences from the BD21 v2.1 annotation were queried against the Oryza sativa v7 MSU protein database. For blastn v2.8.1 [13], the same transcript sequences were queried against a local copy of NCBI’s nt database. For pblat v36x2 [14], all human transcript sequences from the Gencode v29 release were used as a query against GRCh38.
Results
Germline variant detection pipeline speed and scalability
The pipelines for germline variant discovery were tested using a 50× WGS library from the NA12878 sample of Illumina's Platinum Genomes project (ENA study PRJEB3381) [15]. The baseline run of GATK4 took over 100 h on the x86 system mainly due to the HaplotypeCaller step (Table 1). The most significant speed improvements (Fig. 1A) were demonstrated with single threaded PairHMM and splitting the hg38 genome into 32 scattered intervals (two per x86 core); this also allowed for parallelization of the BaseRecalibrator and ApplyBQSR steps. This manual form of multithreading brought the nearly 107-h runtime down to just under 24 h (Table 1). On the POWER9 with SMT4, the most efficient use of resources was observed when 2 intervals were run per core with each using 2 PairHMM threads (Fig. 1A) which yielded a ~10 h decrease in runtime (–42.4%) compared to x86 with lower times in the BWA, MarkDuplicates, and HaplotypeCaller steps.

Variant calling pipelines' speed

Variant calling pipelines’ scalability. (A) To determine the most efficient way of parallelizing GATK’s HaplotypeCaller, different combinations of scattered intervals and PairHMM OpenMP threads were tested on x86 and Power9 systems. The recorded times also include the CombineGVCFs step. (B) The scalability of GATK’s HaplotypeCaller pipeline on x86 and Power9 was tested with varying amounts of compute resources alongside Sentieon’s DNAseq and Parabricks. (C) Scalability of GATK’s Mutect2 pipeline on x86 and Power9 was tested with varying amounts of compute resources alongside Sentieon’s TNseq and TNscope. At the time of this analysis, Parabricks had not yet ported their somatic pipeline to Power9 therefore it could not be tested.
The Sentieon DNAseq/DNAscope pipelines reduced runtimes even further to under 8 h with much faster BWA, MarkDuplicates, and HaplotypeCaller steps. Sentieon’s version of BWA finished ~3 h earlier (–38.2%) than stock on the same x86 node. Marking duplicate reads only took 39 minutes whereas previously mentioned pipelines measured that time in hours. Finally, the HaplotypeCaller step took just over 1 h for Sentieon’s pipeline. Nearly identical runtimes were observed for DNAseq and DNAscope pipelines with the latter being Sentieon’s proprietary algorithm and not a reimplementation of HaplotypeCaller. The fastest analysis performed was Parabricks which yielded a genomic VCF (GVCF) file in 2 h 21 min. When set to output VCF directly, with no GVCF conversion, a faster runtime of 2 h 3 min was observed.
Stock GATK did not scale linearly due to having multiple single threaded steps (Fig. 1B); this is in contrast to Sentieon’s implementation which was almost completely multithreaded allowing for much better scalability. In GPU scalability testing, Parabricks hit diminishing returns when adding a fourth GPU which only reduced runtime by ~23 min (–13.7%) whereas going from two to three GPUs reduced the runtime by about an hour (–25.8%).
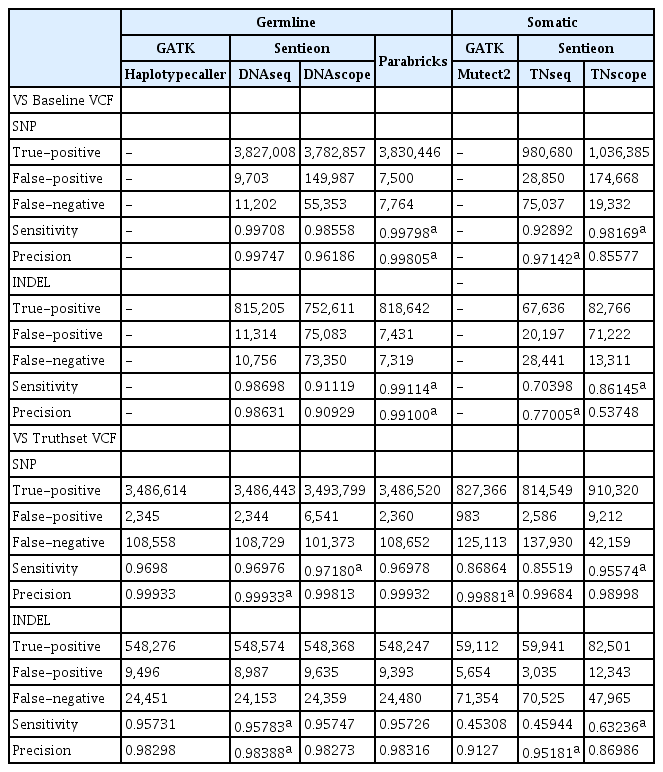
Germline variant detection pipeline accuracy
To determine the accuracy of the various analyses, GATK’s concordance tool was utilized to compare the final VCF outputs to GATK4’s baseline VCF and the NA12878 Platinum Genomes truthset VCF (Table 2). Parabricks most closely matched the GATK baseline run with 99.8% accuracy and precision for single nucleotide polymorphisms (SNPs) and 99.1% accuracy and precision for INDELs. When the output was compared with the version of GATK Parabricks was designed to match (v4.0.4), accuracy and precision were both 99.99% (data not shown). Sentieon’s DNAseq pipeline scored 99.7% for accuracy and precision in calling SNPs, but had around one percentage point decrease for INDEL calling.
Variant calling pipelines' accuracy
In the truthset comparison, Sentieon’s DNAscope yielded the highest SNP sensitivity by calling ~7,000 SNPs that the other callers missed; however, this increase in sensitivity comes at the cost of a loss in precision due to an additional ~4,000 false-positive SNPs. Despite Sentieon’s DNAseq pipeline having the lowest sensitivity and precision for INDELs in the previous comparison, here it ranks highest on both fronts due to it calling ~200–300 more true-positive INDELs that the other pipelines missed and having ~500 fewer false-positives.
Somatic variant detection pipeline speed
To test the performance of the somatic variant calling pipelines, the cancer like mixture of two Genome in a Bottle samples, NA12878 and NA24385, constructed by the Hartwig Medical Foundation and Utrecht Medical Center [16], was utilized. The baseline Mutect2 run took the longest at over 118 h due to the minimally parallelized Mutect2 step. Manually parallelizing this step using scattered intervals allowed for a reduction in total runtime to ~23.5 h on one of our x86 nodes and ~18.5 h on the POWER9 node. Sentieon’s TNseq pipeline reduced this even further to ~7.5 h and their TNscope pipeline was the fastest at ~3.5 h.
Of the steps unique to the Mutect2 “Best Practices” pipeline, Mutect2 and GetPileupSummaries account for over 99% of the total time. While GATK v4.1.0 allows for Mutect2 to be manually parallelized via scattered intervals and a subsequent MergeVCF step, there is no built-in method to merge the output of multiple GetPileupSummaries jobs. This fact hurt the scalability of the pipelines on both x86 and POWER9 systems with Sentieon’s pipelines not only being faster, but also seeing greater reductions in time when given more compute resources (Fig. 1C); however, in GATK v4.1.1 the GatherPileupSummaries tool was introduced which would allow for both steps to be parallelized.
Somatic variant detection pipeline accuracy
The accuracy of the Mutect2 based pipelines was analyzed in a similar fashion to the assessment of the HaplotypeCaller based pipelines via GATK’s Concordance tool (Table 2). TNseq had a higher amount of variation when compared to Mutect2 v4.1.0 than DNAseq had to HaplotypeCaller v4.1.0; however, when TNseq was compared against the specific version of Mutect2 it was designed to mimic (v4.0.2.1), the results were more similar with accuracy and sensitivity both over 99.5% (data not shown).
Benchmarking other bioinformatic tools: POWER9 for bioinformatics
To assess how well POWER9 handles bioinformatic workloads the performance of ten commonly used alignment/mapping tools were compared when run on our Intel x86 nodes and the IBM POWER9 node: STAR, BBMap, Tophat, HISAT2, BWA MEM, Bowtie, Bowtie2, blastx, blastn, and pblat a parallelized version of BLAT [17]. Each tool was run using default settings with the same workload on both x86 and POWER9. This is not a comparison of the tools themselves; some similar tools were given different workloads, such as STAR and Tophat, to allow for meaningful runtimes. Each tool was run with the following resource configurations to allow for thread-vs-thread and core-vs-core comparisons: x86-16t/8c, x86-32t/8c, POWER9-16t/4c, and POWER9-32t/8c.
For thread-vs-thread comparisons, the results are somewhat split between similar runtimes and a slight edge to x86 threads (Fig. 2). STAR, HISAT2, and Bowtie, achieved nearly identical runtimes on both platforms. BBMap, Tophat, BWA MEM, Bowtie2, and blastx performed better with an equal number of x86 threads, while blastn ran nearly twice as fast with an equal number of POWER9 threads and pBLAT had a slight edge. In the core-vs-core performance comparison, the POWER9 architecture resulted in lower runtimes in every instance.
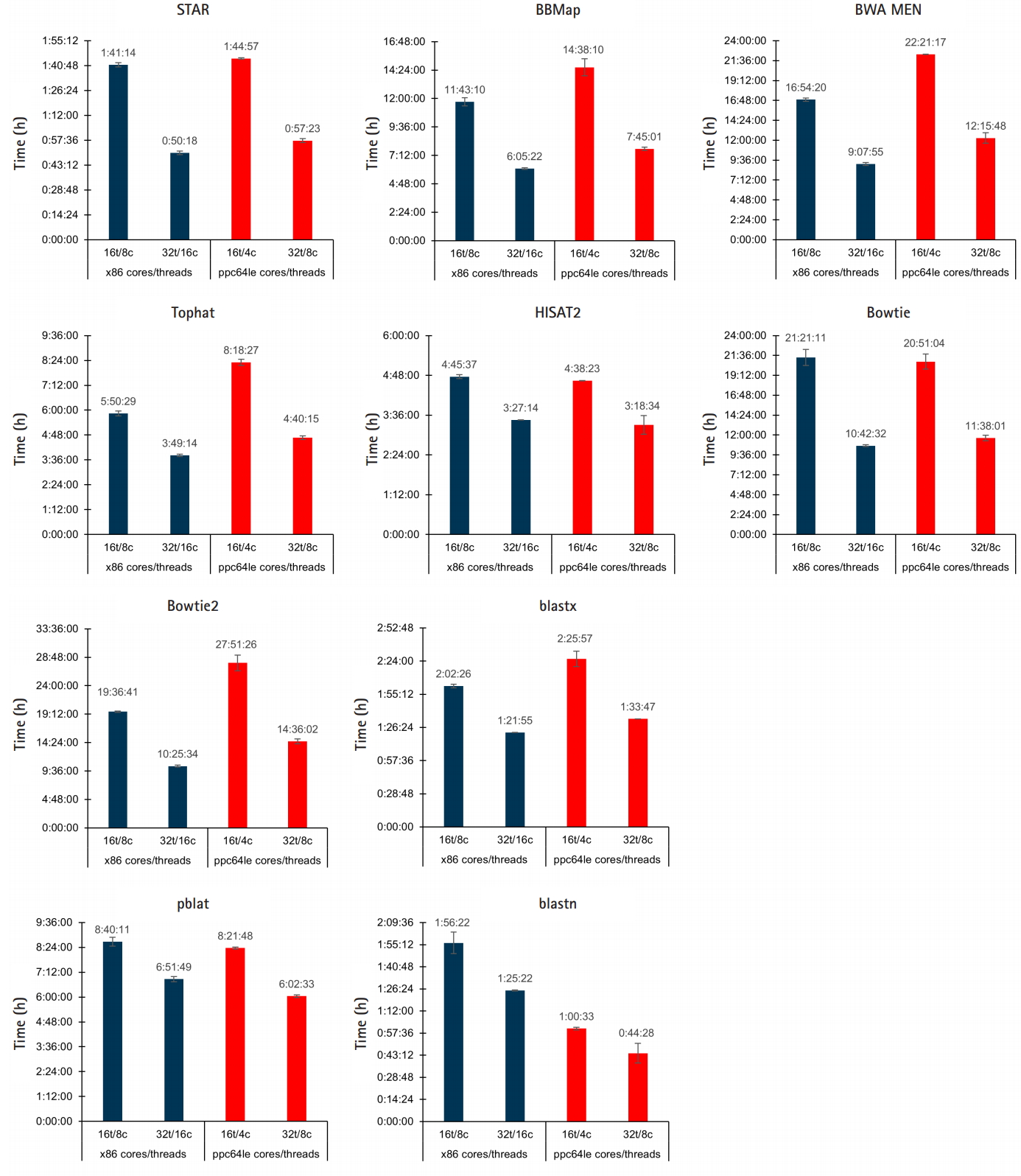
x86/POWER9 performance comparison of aligners/mappers. The performance of 10 different tools for alignment/mapping was compared between POWER9 and ×86 systems. Jobs were run in triplicate across different days; averaged results are shown in the graphs with the error bars representing standard deviation.
Discussion
Both Parabricks and Sentieon offer highly accelerated GATK algorithms that greatly reduce variant calling processing time. Parabricks’s utilization of the higher number of cores available on a GPU compared to a CPU allows for a much faster processing time of a single sample compared to Sentieon. However, the legacy of algorithm development in a CPU environment compared to a GPU for NGS pipelines has impacted the relative number of CPUs available compared to GPUs within an institution. The value of being able to process a single sample in ~2 h should not be discounted, however, especially in the age of precision medicine. Delivering “fast” genome sequencing to help diagnosis a newborn in a neonatal intensive care unit or to identify a somatic variant that can be used in treatment selections is becoming a reality for many institutions.
Our testing of Sentieon’s ability to reproduce GATK’s output yielded similar results to a previous assessment done by Kendig et al. [18]; however, the output from Parabricks was essentially identical to the targeted version which may make it more attractive to those within the research community. If GATK compliance is less of a concern, Sentieon does offer their own proprietary algorithms for variant calling which did perform better when compared to the VCF truthsets used in this study.
While the CPUs used in this comparison are all based on 14nm microarchitectures, the Intel CPUs in our x86 nodes are a few years old, and to do a true x86 versus POWER9 comparison a newer Intel CPU would be needed. Despite this, we felt that these benchmarking comparisons would shed light on POWER9’s ability to handle bioinformatic workloads and prove useful to researchers in designing their compute infrastructure.
The POWER9 architecture performed well in the core-vs-core comparisons. Part of this advantage comes from IBM’s implementation of simultaneous multithreading, which is superior to Intel’s Hyper-threading by allowing for twice as many threads to run simultaneously on the same core. This analysis demonstrated that even in instances where the tools were originally coded to take advantage of Intel specific instruction sets such as SSE2, the total runtime was lower on POWER9 than x86 with identical core counts. However, this does allude to an issue that can arise when using a POWER9 system: not all bioinformatic programs that were originally written for x86 systems can easily compile and run on the POWER9 architecture.
Notes
Authors’ Contribution
Conceptualization: KRF, ELC. Data curation: KRF, ELC. Formal analysis: KRF, ELC. Funding acquisition: ELC. Methodology: KF. Writing - original draft: KRF, ELC. Writing - review & editing: KRF, ELC.
Conflicts of Interest
No potential conflict of interest relevant to this article was reported.
Acknowledgements
We thank both Parabricks and Sentieon for trial licenses of their software suites. We also thank Ruzhu Chen from IBM for POWER9 versions of BWA, Bowtie2, and Bowtie.
This work was supported by the Lisa Dean Moseley Foundation (PI Crowgey); and the Nemours Alfred I duPont Hospital for Children.