Eukaryotic DNAJ/K Database: A Comprehensive Phylogenomic Analysis Platform for the DNAJ/K Family
Article information
Abstract
Proteins in DNAJ/K families are ubiquitous, from prokaryotes to eukaryotes, and function as molecular chaperones. For systematic phylogenomics of the DNAJ/K families, we developed the Eukaryotic DNAJ/K Database (EDD). A total of 12,908 DNAJs and 4,886 DNAKs were identified from 339 eukaryotic genomes in the EDD. Kingdom-wide comparison of DNAJ/K families provides new insights on the evolutionary relationship within these families. Empowered by 'class', 'cluster', and 'taxonomy' browsers and the 'favorite' function, the EDD provides a versatile platform for comparative genomic analyses of DNAJ/K families.
Introduction
Ubiquitous heat shock proteins (HSPs) play essential roles as molecular chaperones that protect cells through protein folding as a stress response under heat shock [1]. The HSPs are well conserved in all eukaryotes and prokaryotes [2]. The HSPs are classified on the basis of their approximate molecular mass (e.g., the 70-kDa species is the Hsp70 family). DNAJ and DNAK are members of the Hsp40 and Hsp70 families, respectively [3]. These proteins are known to cooperate in many cellular processes, such as DNA replication, protein folding, protein export, and stress response in an ATP hydrolysis-dependent manner [4-6]. The cooperation of DNAJ and DNAK is dependent on the interactions between the J domain of DNAJ and the ATPase domain of DNAK [7].
DNAJ proteins were classified using the J, zinc finger, and carboxy-terminal domains [8]. Type I DNAJs contain all three domains, while type II proteins have a J domain linked directly to a carboxy-terminal domain without a zinc finger domain. The type III proteins include only the J domain. However, such domain architectures of DNAJ were not deliberated on most eukaryotic genome annotations, which might cause overestimation of DNAJ entries [9, 10]. Likewise, many studies of DNAKs have been used without any unified nomenclature or notation [11, 12], although ATPase and peptide-binding domains had been defined [13]. Recent classifications and identifications based on functional domains of the DNAJ/K families revealed 22, 89, and 41 DNAJs [9, 10, 14], and 14, 18, and 17 DNAKs [11, 12, 15] in the yeast, Arabidopsis, and human genomes, respectively. However, there is no informative platform that archives the previously identified DNAJ/Ks. Furthermore, only a few genomes have systematically identified DNAJ/K families, although hundreds of genomic sequences are publicly available. This problematic circumstance has demanded the development of a comprehensive platform that archives sequence information, classifies them according to their domain structures, and analyzes them using bioinformatics tools. The platform should provide user-friendly interfaces and easy access. Therefore, we developed a web-based phylogenomic platform called the Eukaryotic DNAJ/K Database (EDD).
Methods and Results
Identification and classification of DNAJ/K family from 339 eukaryotic genomes
An automated pipeline was programmed to identify and classify the DNAJ/K families (Fig. 1). All protein sequences of the 339 genomes deposited in the Comparative Fungal Genomics Platform (CFGP; http://cfgp.snu.ac.kr) [16] were filtered according to the following description. Six InterPro terms (release 12.0) for DNAJ (IPR012724, IPR008971, IPR003095, IPR001305, IPR002939, and IPR001623) and three for DNAK (IPR013126, IPR001023, and IPR012725) were used to retrieve corresponding sequences. When the J domain or any of the DNAK domains was at least 50 amino acids (aa), it was defined as 'putative', and the others were tagged as 'candidate DNAJ/Ks'. The HPD tripeptide motif and glycine-rich region were identified from the 'putative DNAJ' sequences. The DNAK family was clustered by sequence similarity (BLAST E-value cutoff e-5) using the Tribe Markov clustering (MCL) algorithm [17], because no class has been made in this family. Finally, 12,908 DNAJs and 4,886 DNAKs were identified and deposited into EDD. In the DNAJ family, 895, 3,172, and 8,700 proteins were classified as type I, II, and III, respectively. Twenty-one clusters were determined in DNAK, and 4,853 proteins (99.1%) belonged to the first four clusters.
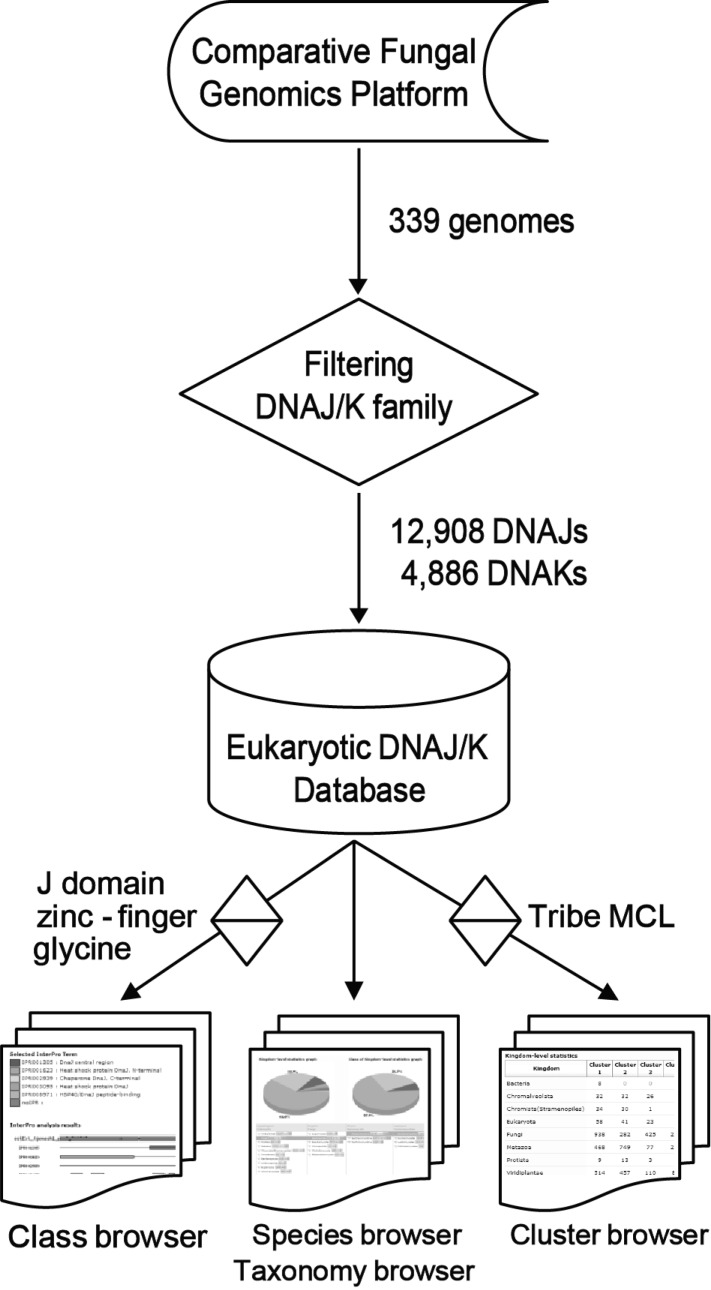
System architecture and data processing pipeline in the Eukaryotic DNAJ/K Database. MCL, Markov clustering.
Web-based interfaces of the EDD
First, all protein and nucleic acid sequences identified as DNAJ/Ks can be accessed according to class, species, and cluster through user-friendly interfaces, such as the 'class' and 'cluster' browsers on the EDD website. For example, statistics pages of each class were displayed using tables and diagrams in the 'class' browser. The statistics pages are automatically updated when new data are added to the EDD. Secondly, the EDD allows users to browse the detailed information on DNAJ/Ks and to analyze it via 'favorite'. It is a customized cyber-workbench where users can create folders, store favored items, and perform 10 bioinformatics analyses, such as BLAST search, BLASTMatrix, ClustalW, DNAJ/K statistics, a DNAJ class viewer, a DNAJ/K domain viewer, and a glycine ratio viewer. Especially, 'favorite', implemented in the EDD, is specialized for the functional analysis of DNAJ/K proteins (e.g., DNAJ/K domain view). The data saved in 'favorite' can be shared with CFGP 2.0 for further comparative analysis [16]. Finally, a highlighted function of the EDD is a 'taxonomy' browser powered by the 'Species-driven User Interface', which provides an interactive interface for displaying the taxonomical hierarchy for DNAJ/Ks. Users can drag and drop any taxon or taxa and perform sequence download, statistics, class and cluster analyses, ClustalW alignment, and BLAST search.
Conclusion
The comprehensive information on DNAJ/Ks conserved in 339 genomes over seven phyla is a useful resource for molecular chaperone studies in eukaryotes. Phylogenetic analysis between phyla or kingdoms as well as genomic analysis within a species can be performed in the EDD. The user-friendly web interfaces and various analysis tools implemented in this database will accelerate the management of large-scale data. The EDD will be a novel platform for phylogenomic studies and a model for comprehensive genomic analyses.
Acknowledgments
The National Research Foundation of Korea (2012-0001149 and 2012-0000141), the TDPAF (309015-04-SB020), and the Next-Generation BioGreen 21 Program of Rural Development Administration in Korea (PJ00821201) grants to Y.-H. Lee. K. Cheong is grateful for a graduate fellowship through the Brain Korea 21 Program.