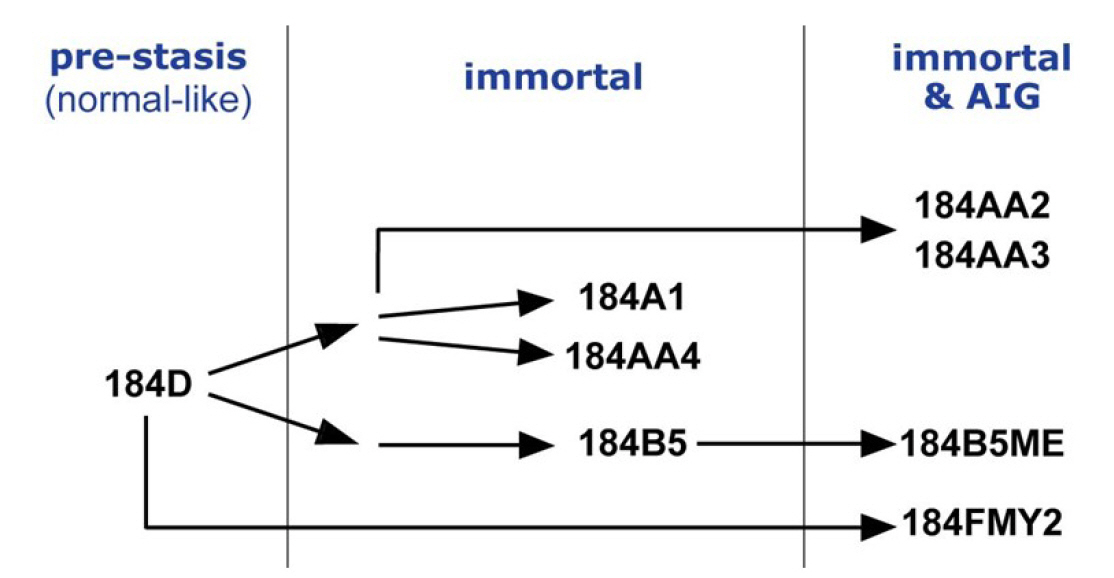
Introduction
Breast cancer is the most common cancer diagnosed among women in the United States (excluding skin cancers). It is the second leading cause of cancer death among women after lung cancer [1]. It is curable in ~70%ŌĆō80% of early-stage patients before metastasis. However, advanced breast cancer with distant organ metastases is considered incurable with currently available therapies [2]. Therefore, it is crucial to understand molecular characteristics that are associated with the development of breast cancer and to identify molecular biomarkers. A cell-based model system is essential for an in-depth study of molecular events during the human breast tumorigenesis. Human mammary epithelial cell (HMEC) lines, developed from normal breast tissues, are an ideal in vitro cell line model recapitulating early events of breast tumorigenesis [3] (see also https://hmec.lbl.gov/mock/history.html). Briefly, 184D is primary culture cells obtained from the reduction mammoplasty specimen 184. Most 184D cells underwent cell death (so-called the stasis barrier). 184D cells were treated with a mutagen benzo[a]pyrene or transformed by c-MYC transduction to overcome the stasis barrier. They were clonally selected to yield seven HMEC lines ([4-8], summarized in Fig. 1). In this study, we obtained and analyzed whole-genome sequencing (WGS) data from HMEC lines, which will help understand early breast carcinogenesis at the genomic level.
Methods
WGS library construction and sequencing
We used the QIAamp DNA Mini Kit (Qiagen, Carlsbad, CA, USA) to isolate gDNA from HMEC cultures. The quantity of the extracted gDNA was analyzed with an ND-1000 spectrophotometer (Thermo Fisher Scientific, Waltham, MA, USA). For WGS library construction, we used the TruSeq DNA library Prep Kit (Illumina, San Diego, CA, USA) according to the manufacturerŌĆÖs instructions. For WGS, paired-end sequencing was performed on the Illumina HiSeq X Ten sequencing instrument, yielding ~150-bp short sequencing reads.
Data analysis
Raw sequence reads were aligned to the human reference genome 19 using Burrows Wheelers Aligner [11], and duplicate reads were removed using Picard (Broad Institute). We used Qualimap 2 to evaluate next-generation sequencing alignment data [12]. Then, the remaining reads were calibrated and realigned using the Genome Analysis Toolkit [13]. The realigned Binary Alignment Map files were analyzed using Strelka2 [14] to detect somatic single-nucleotide variants and insertions/deletions. The relative distribution of single-base substitutions was analyzed by the Maftools [15]. We used HOMER to annotate somatic mutation to the hg19 genome [16]. For driver mutation analysis, we download the driver gene list from the IntOgen cancer mutation browser [17]. For all programs, we used the default parameter setting.
Data availability
The whole-genome data are available in the Korean Nucleotide Archive (KoNA, https://kobic.re.kr/kona) and Sequence Read Archive (SRA, https://www.ncbi.nlm.nih.gov/sra) public database with the accession number PRJKA220370 and PRJNA913438.
Results and Discussion
Quality and quantity of the sequencing data
We performed WGS on a total of eight HMEC cultures (shown in Fig. 1): pre-stasis 184D, its derivatives immortalized cell lines (184A1, 184AA4, and 184B5), and immortalized ones that further acquired AIG (184AA2, 184AA3, 184B5ME and 184FMY2). First, we assessed the quality and quantity of the WGS data, including mapping rates, genome coverage, scores of the mapping quality, and duplicate reads using Qualimap 2. These values are summarized in Table 1. Briefly, the mapping rate and scores of the mapping quality of the eight samples were higher than 85% and 53%, respectively. In addition, the average genome coverage was more than 30├Ś (between 31.84├Ś and 42.84├Ś) in all eight samples. WGS data with 30├Ś sequence coverage is appropriate for comprehensively identifying tumor-specific somatic mutations [18]. These results indicate that the quality and quantity of our WGS data were satisfactory for mutational analysis in HMEC cultures.
Mutation patterns identified from the HMEC model
We analyzed somatic mutations from the WGS data. 184D cells are the primary culture of normal breast tissue and yet-to-be immortalized. Therefore, we considered 184D as normal breast tissue and used its genome sequence as a reference sequence when analyzing WGS data of the other seven HMEC lines that are cancer progression series.
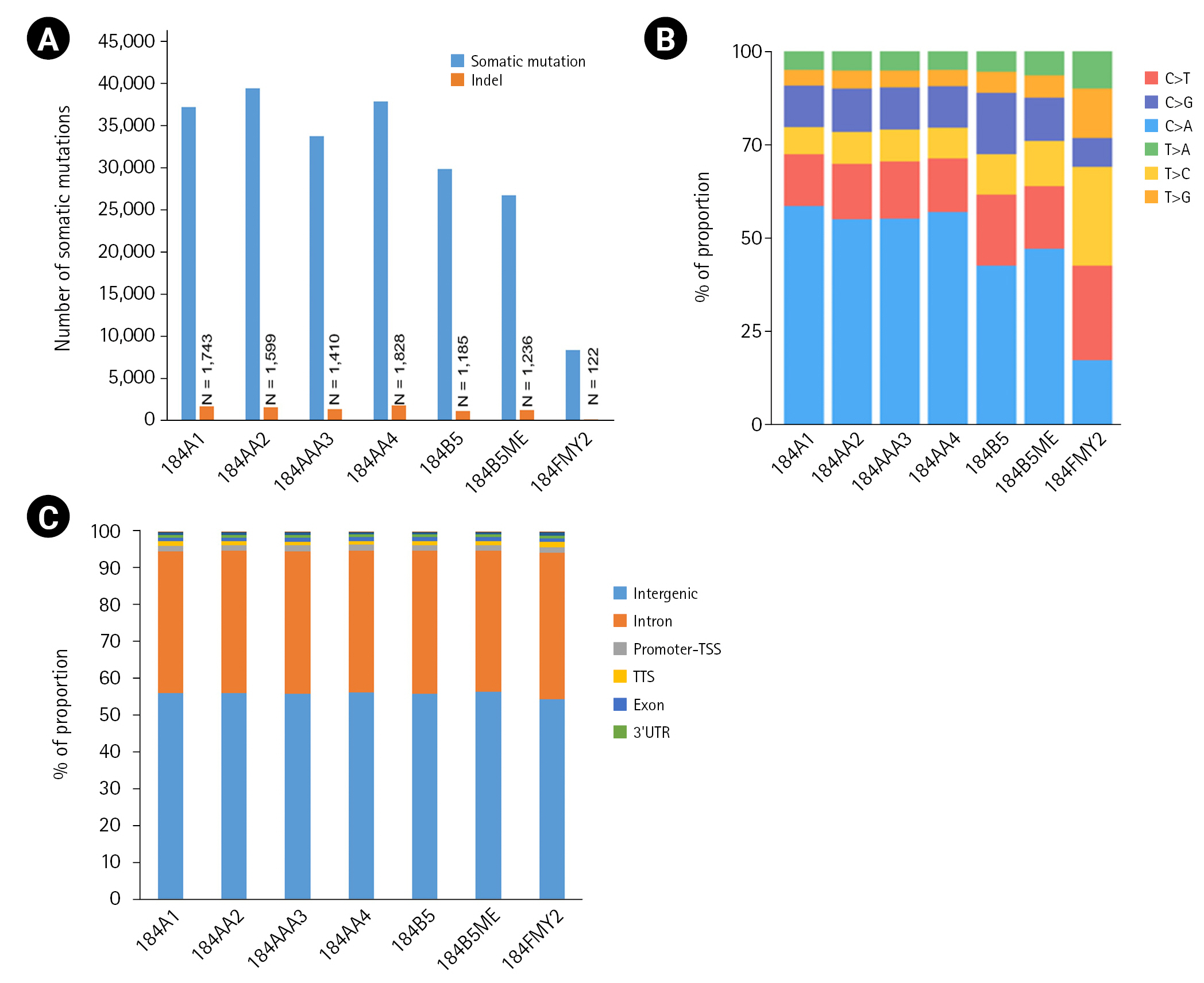
Among the seven HMEC lines, the number of somatic mutations per sample ranged from 8,393 to 39,564, with an average of 30,591 (Fig. 2A). In particular, 184FMY2 had notably low somatic mutation frequency (n = 8,393), in agreement with the fact that it had been made by c-MYC transduction, whereas the other HMEC lines were treated with benzo[a]pyrene. Next, we examined the pattern of base substitutions. Except for 184FMY2, we observed that ~50% of mutations were C>A and that ~30% were C>T and C>G transversions (Fig. 2B), similarly to a previous study [19]. We annotated those somatic mutations to the hg19 reference genome and observed that most somatic mutations were located in the intergenic and intronic regions (Fig. 2C).
Since non-synonymous mutations are likely to be essential and are functionally annotatable, we focused on them. The number of mutations affecting protein-coding genes was 52 to 361 in each sample (data not shown). Then, we performed the driver mutation analysis using the IntOGen cancer mutation browser [17] and observed that 36 non-synonymous mutations in the HMEC cancer progression series coincided with the cancer driver mutations (Table 2). Further study will be needed to validate whether the mutated genes are genuinely associated with breast carcinogenesis.
In this study, we generated WGS data and analyzed mutation profiles in the HMEC cancer progression series because genetic mutations are one of the most significant factors in determining breast cancer progression and therapeutic management [20]. We hope that our WGS data of HMEC lines will provide useful information to breast cancer researchers and clinicians.